深度学习基础
目录
1. 神经网络基本结构
1.1 线性模型
最简单的神经网络就是线性模型:
y^=wx+b
- w(权重/weight):控制输入 x 对输出 y^ 的影响程度(斜率)
- b(偏置/bias):决定 x=0 时的输出基准值(截距)
1.2 为什么需要多层
单层线性模型只能拟合线性关系。直觉上,堆叠多层似乎能拟合更复杂的函数。但有一个关键问题——如果没有非线性变换,多层线性网络等价于单层。
假设一个两层网络:
y^=w2(w1x+b1)+b2=w2w1⋅x+w2b1+b2=W′x+b′
无论堆多少层,最终都可以化简为 y^=Wx+b。激活函数的引入正是为了打破这种线性等价性,使网络有能力拟合复杂函数。
2. 损失函数
损失函数(Loss Function)衡量模型预测值与真实值之间的差距。不同任务需要不同的损失函数。
2.1 均方误差(MSE)
适用场景:回归任务(预测连续值)
LMSE=n1i=1∑n(y^i−yi)2
推导逻辑:直接用 (y^−y) 有正负号歧义(−2 和 +2 偏离程度一样但符号不同),取平方消除歧义。
局限性:对错误预测的惩罚增长平缓。举例:
| 预测概率(正确类别) |
MSE |
| 0.9 |
0.02 |
| 0.6 |
0.40 |
| 0.1 |
1.62 |
| 0.01 |
1.96 |
模型几乎完全判错(p=0.01),MSE 不到 2,惩罚太轻。
2.2 交叉熵损失(Cross-Entropy Loss)
适用场景:分类任务(预测类别概率)
LCE=−i=1∑Cyilog(pi)
其中 y 是 one-hot 编码的真实标签(只有一个位置为 1),p 是模型预测的概率分布,C 是类别数。实际等价于 −log(p正确)。
推导逻辑:用正确类别预测概率的负对数,log 函数在接近 0 时趋于 −∞,所以 −log(p) 对低概率的惩罚极其强烈。
同样四个情况对比:
| 预测概率(正确类别) |
交叉熵 |
MSE |
| 0.9 |
0.105 |
0.02 |
| 0.6 |
0.511 |
0.40 |
| 0.1 |
2.303 |
1.62 |
| 0.01 |
4.605 |
1.96 |
交叉熵的惩罚指数级增长,这就是分类任务几乎都用交叉熵而非 MSE 的原因。
2.3 KL 散度(KL Divergence)
适用场景:让一个分布逼近另一个分布(如知识蒸馏、RLHF、VAE)
DKL(p∥q)=−i∑pilogpiqi=i∑pilogqipi
其中 p 是真实分布,q 是模型预测分布。
核心性质:
- p=q 时,DKL=0(完全匹配)
- p 和 q 差异越大,KL 散度越大
- 不对称:DKL(p∥q)=DKL(q∥p)("用 q 描述 p" 和 "用 p 描述 q" 信息量不同)
示例:p=[0.6,0.3,0.1],q=[0.7,0.2,0.1]
H(p,q)≈0.907,H(q,p)≈1.029
结果不同,说明交叉熵(以及 KL 散度)是有方向的。
2.4 信息熵(Entropy)
KL 散度的理解需要先理解信息熵。信息熵衡量一个概率分布的不确定性:
H(p)=−i∑pilog(pi)
示例:
| 分布 |
信息熵 |
| [0.5,0.5](完全不确定) |
1.0 bit |
| [0.9,0.1](比较确定) |
0.469 bit |
| [1,0](完全确定) |
0 bit |
规律:分布越均匀(越不确定),熵越大;分布越偏(越确定),熵越小。
2.5 三者的关系
交叉熵H(p,q)=信息熵H(p)+KL散度DKL(p∥q)
- 信息熵 H(p):真实分布固有的不确定性,和模型无关,优化过程中是常数
- 交叉熵 H(p,q):用 q 描述 p 的总信息量
- KL 散度 DKL(p∥q):交叉熵扣除固有部分后,纯纯衡量"两个分布的差异"
最小化交叉熵 ≈ 最小化 KL 散度(因为 H(p) 是常数),训练效果等价。但在使用场景上:
| 损失函数 |
适用场景 |
特点 |
| MSE |
回归任务 |
对异常值敏感,惩罚增长平缓 |
| 交叉熵 |
分类任务 |
惩罚指数级增长,对错误预测惩罚强 |
| KL 散度 |
分布匹配 |
不对称,衡量分布间"距离" |
3. 梯度下降与反向传播
3.1 梯度下降的基本思想
已知损失函数 L 关于参数 w 的梯度 ∂w∂L:
- 梯度为正 → L 随 w 增大而增大 → w 应减小
- 梯度为负 → L 随 w 增大而减小 → w 应增大
始终往梯度的反方向更新,这就是梯度下降:
w←w−η⋅∂w∂L
其中 η 是学习率(learning rate),控制每步的大小。
3.2 批量策略的演进
批量梯度下降(Batch GD)
每轮更新遍历所有 n 个样本,取梯度均值后更新一次。
- 优点:梯度方向最准确
- 缺点:n=100 万时,每更新一步就要算完所有梯度,太慢
随机梯度下降(SGD)
每个样本计算一次梯度就更新一次。
小批量梯度下降(Mini-batch SGD)
每次取一个 batch(如 1024 条)算梯度并更新。
- 优点:在计算效率和梯度准确性之间取得平衡
- 这是实际训练中最常用的方式
| 方法 |
每次更新的样本数 |
梯度准确性 |
计算效率 |
| Batch GD |
全部 n 条 |
最高 |
最低 |
| Mini-batch SGD |
一个 batch |
中等 |
中等 |
| SGD |
1 条 |
最低 |
最高 |
3.3 反向传播(Backpropagation)
反向传播的核心是链式法则(Chain Rule)——将复合函数的导数拆分为各部分导数的乘积。
以两层网络为例:
xw1,b1z1=w1x+b1fa1=f(z1)w2,b2z2=w2a1+b2=y^
损失 L 对第一层权重 w1 的梯度,需要通过整条链传递:
∂w1∂L=来自损失∂z2∂L⋅第二层权重w2⋅激活函数导数f′(z1)⋅输入∂w1∂z1
关键洞察:中间的 w2⋅f′(z1) 就是缩放因子——梯度从第二层传到第一层时要乘上它。如果是十层网络,就要连乘十个这样的缩放因子。
4. 梯度消失与梯度爆炸
4.1 问题产生
深层网络中,梯度从输出层反向传回输入层,每经过一层都要乘一个缩放因子(由权重 w 和激活函数导数 f′(z) 组成):
浅层梯度=深层梯度×每层∏(权重×激活函数导数)
- 梯度消失:每层的缩放因子 <1,连乘后趋近于 0 → 浅层参数几乎不更新
- 梯度爆炸:每层的缩放因子 >1,连乘后趋于无穷 → 参数更新失控,loss 变成 NaN
典型例子:Sigmoid 的导数最大只有 0.25,乘 10 层就是 0.2510≈0.000001,梯度基本消失。
4.2 解决方案
这个问题是深度学习三大基石问题的根源,后续多个模块都是为了解决它而设计的:
- 归一化:让每层输出保持在合理范围,防止梯度过度放大/缩小(第 5 节)
- 激活函数:用导数更好的激活函数替代 Sigmoid(第 6 节)
- 参数初始化:让初始权重的方差恰好使得梯度保持稳定(第 9 节)
5. 归一化
5.1 核心思想
如果每一层的输出都能自动归一化到一个合理的范围内,梯度在传递过程中就不会被过度放大或缩小。
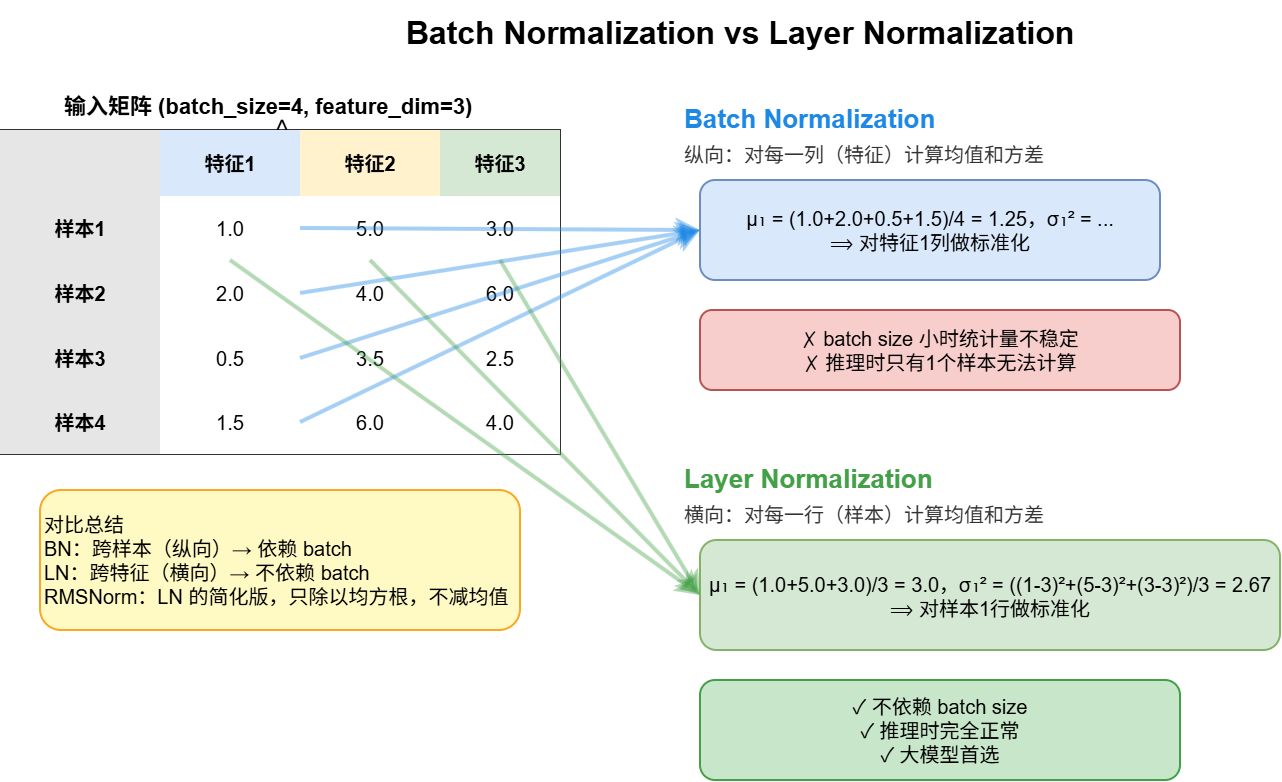
5.2 Batch Normalization(BN)
做法:对当前 batch 内的所有样本,按每个特征维度计算均值和方差。
假设输入形状为 (N,d)(N 是 batch size,d 是特征维度):
- 计算统计量(对每个特征 j):
μj=N1i=1∑Nxij,σj2=N1i=1∑N(xij−μj)2
- 标准化:
x^ij=σj2+ϵxij−μj
- 缩放平移(γ 和 β 是可学习参数):
yij=γjx^ij+βj
问题:
- batch size 小时统计量不稳定(2 个样本算的均值方差远不如 1000 个可靠)
- 推理时只有 1 个样本,batch 统计量根本没法算(需要保存训练时的滑动均值/方差来替代)
5.3 Layer Normalization(LN)
做法:对单个样本的所有特征计算均值和方差。
- 计算统计量(对每个样本 i):
μi=d1j=1∑dxij,σi2=d1j=1∑d(xij−μi)2
- 标准化:
x^ij=σi2+ϵxij−μi
- 缩放平移:
yij=γx^ij+β
优势:不依赖 batch size,batch 多小都没问题,推理时也完全正常。
5.4 BN vs LN 直观对比
以输入矩阵为例:
1
2
3
4
5
| 特征1 特征2 特征3
样本1: 1.0 5.0 3.0
样本2: 2.0 4.0 6.0
样本3: 0.5 3.5 2.5
样本4: 1.5 6.0 4.0
|
- BN:纵向看,对每一列算均值方差。如特征1的均值 = (1.0+2.0+0.5+1.5)/4=1.25
- LN:横向看,对每一行算均值方差。如样本1的均值 = (1.0+5.0+3.0)/3=3.0
5.5 RMSNorm(大模型首选)
RMSNorm 是 LN 的简化版——只除以均方根,不减均值:
RMSNorm(x)=d1∑j=1dxj2+ϵx⋅γ
为什么大模型选 RMSNorm 而非 BN:
- 不依赖 batch size(解决 BN 的核心缺陷)
- 比 LN 计算更简单(不需要减均值),速度更快
- 实验效果与 LN 相当甚至更好
| 方法 |
归一化维度 |
依赖 batch |
推理可用 |
大模型使用 |
| BN |
跨样本(纵向) |
是 |
需要保存统计量 |
否 |
| LN |
跨特征(横向) |
否 |
是 |
早期 Transformer |
| RMSNorm |
跨特征(横向) |
否 |
是 |
LLaMA 等现代模型 |
6. 激活函数
激活函数的作用是引入非线性,让多层网络能拟合复杂函数。
6.1 Sigmoid
f(z)=1+e−z1
将任意输入压缩到 (0,1) 区间,适合二分类输出层。
缺陷:
- 导数最大只有 0.25,深层网络中导致梯度消失
- 非零中心输出(全部为正),影响梯度下降效率
- 计算包含指数运算,速度慢
6.2 ReLU(Rectified Linear Unit)
f(z)=max(0,z)
- z>0 时:f(z)=z,导数为 1
- z≤0 时:f(z)=0,导数为 0
为什么比 Sigmoid 好:只要大部分神经元处于 z>0 区间,梯度连乘时就是一堆 1 相乘,不会消失。
缺陷:
- 神经元死亡(Dead ReLU):一旦某个神经元的 z 持续 <0,输出永远为 0,梯度永远为 0,参数永远不更新,那部分模型容量被浪费
- z=0 处不可导(有折点),优化轨迹不平滑
6.3 LeakyReLU
f(z)={zαzz>0z≤0(α 通常取 0.01)
解决:Dead ReLU 问题。z<0 时梯度是 α(非零),神经元不会完全"死掉"。
6.4 GELU(Gaussian Error Linear Unit)
GELU(z)=z⋅Φ(z)
其中 Φ(z) 是标准正态分布的 CDF。近似公式:
GELU(z)≈0.5z(1+tanh(π2(z+0.044715z3)))
核心思想:不做硬切换,而是平滑过渡。
- z 很大时,Φ(z)≈1,GELU (z)≈z(和 ReLU 正半轴一样)
- z 很小时,Φ(z)≈0,GELU (z)≈0(和 ReLU 负半轴一样)
- z=0 附近圆滑过渡,没有折点
为什么不用 ReLU:ReLU 在 z=0 处有折点(导数突变)。当神经元在 0 附近反复横跳时,梯度在 0 和 1 之间来回切换,优化轨迹不平滑。GELU 的平滑性让训练更稳定。
6.5 SwiGLU
SwiGLU(x)=(xW+b)⊙σ(xV+c)
核心思想:引入门控机制(Gating)——模型自己决定每个维度"放多少信息通过"。
- 输入 x 过两个线性层,分别得到"主路径"和"门控信号"
- 门控信号过 sigmoid 变成 (0,1) 之间的值
- 两个向量逐元素相乘(⊙)
优势:比 GELU 多了可学习的门控,表达能力更强。LLaMA 使用 SwiGLU。
6.6 演进总结
Sigmoid解决梯度消失ReLU解决平滑性GELU可学习门控SwiGLU
7. 优化器
7.1 SGD(随机梯度下降)
w←w−η⋅g
最基础的优化方法,沿梯度反方向走固定步长。
缺陷:固定学习率,在峡谷地形中反复震荡(走 Z 字形),无法自适应不同参数的需求。
7.2 Momentum(动量)
v=βvold+g,w←w−η⋅v
引入"惯性"——连续同方向梯度会加速,方向切换时动量正负抵消自动减速。
解决:SGD 的 Z 字震荡问题。
遗留:步长仍然统一,不能对每个参数分别调节。
7.3 Nesterov(Nesterov Accelerated Gradient)
先按当前动量预判一步,在预判位置计算梯度,如果发现前面是"坑"就提前减速。
解决:Momentum 可能冲过头的问题。
遗留:仍然没有自适应学习率。
7.4 AdaGrad(自适应梯度)
G=Gold+g2,w←w−η⋅G+ϵg
梯度平方累积大的参数(方向陡峭)→ 学习率自动缩小;累积小的参数 → 学习率相对大。
解决:不同参数需要不同学习率的问题。
致命缺陷:G 只加不减,越累积越大。训练后期学习率趋近于 0,几乎停止学习。这是不可逆的问题。
7.5 RMSProp(均方根传播)
v=βvold+(1−β)g2,w←w−η⋅v+ϵg
把"累积所有历史"改成"指数移动平均",远的梯度影响逐渐衰减。
解决:AdaGrad 学习率只降不升的问题。β 通常取 0.9,只关注最近约 10 步的梯度情况。
遗留:仍需手动调学习率 η。
7.6 Adam(Adaptive Moment Estimation)
m=β1mold+(1−β1)g(一阶矩,类似 Momentum)
v=β2vold+(1−β2)g2(二阶矩,类似 RMSProp)
m^=1−β1tm,v^=1−β2tv(偏差修正)
w←w−η⋅v^+ϵm^
解决:把 Momentum(方向加速)和 RMSProp(自适应步长)合二为一,再加上偏差修正解决初始化阶段 m 和 v 偏小的问题。
Adam 逐步计算示例(参数 w=1.0,η=0.01,β1=0.9,β2=0.999):
| 步数 |
梯度 g |
m |
v |
m^ |
v^ |
更新后 w |
| 1 |
0.1 |
0.01 |
0.00001 |
0.100 |
0.01 |
0.990 |
| 2 |
0.5 |
0.059 |
0.00026 |
0.311 |
0.13 |
0.981 |
| 3 |
0.2 |
0.073 |
0.00030 |
0.269 |
0.10 |
0.973 |
| 4 |
0.1 |
0.076 |
0.00031 |
0.221 |
0.078 |
0.965 |
注意第 2 步梯度突然变大(0.5),v 从 0.01 跳到 0.13 → 分母变大 → 步子自动缩小。这就是自适应学习率的机制。
缺陷(Weight Decay 问题):如果把权重衰减 λw 加到梯度 g 里再送入 Adam,衰减力度会被 m 和 v 的统计量稀释。
7.7 AdamW(Adam + 解耦权重衰减)
Adam(有问题的做法):把 λw 混入梯度一起算 m 和 v → 衰减力度被自适应学习率干扰
AdamW(正确的做法):
- 先正常用 Adam 更新(只用 g 算 m 和 v):w′=w−η⋅m^/(v^+ϵ)
- 再单独做权重衰减:w=w′−η⋅λ⋅w
效果:权重衰减力度始终恒定,正则化效果更可靠。大模型训练的标准选择。
7.8 优化器演进总结
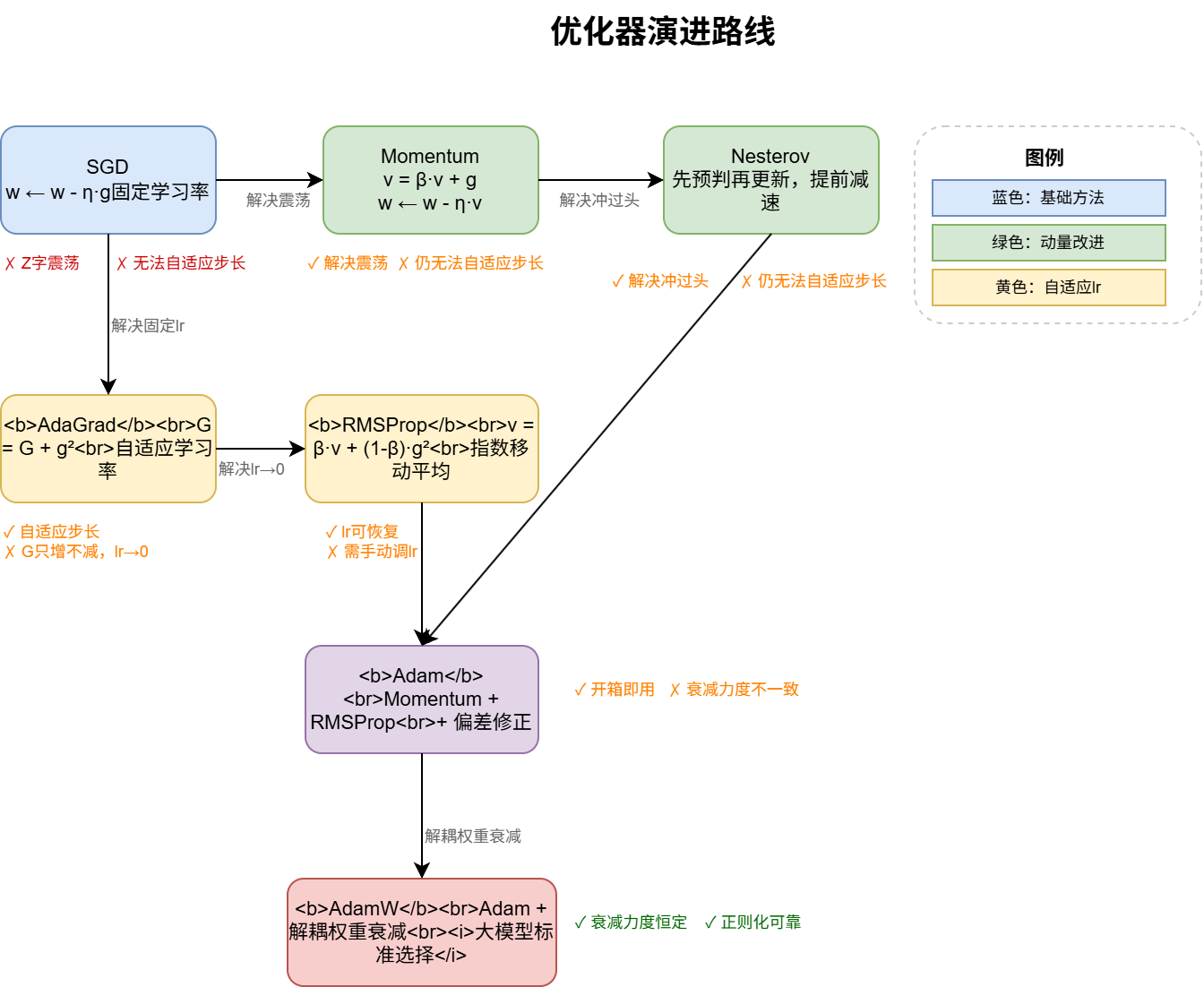
SGDZ字震荡Momentum冲过头Nesterov固定lrAdaGradlr→0RMSProp
Momentum + RMSProp + 偏差修正⇒Adam衰减被稀释AdamW
8. 正则化
正则化的核心目标是防止过拟合——避免模型对训练数据死记硬背,提高泛化能力。
8.1 Weight Decay(权重衰减)
原理:在损失函数上加 L2 正则项:
Ltotal=L原始+2λ∑wi2
更新公式多出 −ηλw,每轮参数都会被乘以 (1−ηλ),不断"缩水"。
为什么有效:参数值大时,输入微小变化会导致输出剧烈波动——模型过于"敏感",开始拟合噪声。Weight Decay 让模型偏好小权重,函数更平滑。
效果:如果某个参数对降低 loss 没什么帮助,会被压向 0,相当于自动"精简"模型。
注意:AdamW 把权重衰减从梯度统计中解耦(第 7.7 节),效果更可靠。
8.2 Dropout
做法:训练时以概率 p 随机将部分神经元的输出置为 0。
为什么有效:
- 每次训练时随机关掉不同神经元 → 等价于训练多个不同子网络的集成(ensemble)
- 单个神经元不能依赖特定其他神经元的存在 → 被迫学到更鲁棒的特征
- 推理时所有神经元保留,相当于多个子网络投票平均
注意事项:
- 训练时随机丢弃,推理时不丢弃
- 训练时保留的输出要乘以 1/(1−p) 补偿,保持期望值一致
8.3 Label Smoothing(标签平滑)
问题:one-hot 标签 [1,0,0] 迫使模型把正确类别的概率推向极端值(0.99 → 0.999),但 0.99 和 0.999 没有本质区别,却导致 logits 膨胀和过度自信。
做法:将 one-hot 标签"抹平":
ysmooth=(1−ε)⋅yonehot+Kε
ε 通常取 0.1,K 是类别数。例如三分类(猫):
[1.0,0.0,0.0]ε=0.1[0.933,0.033,0.033]
效果:
- 模型不再被逼迫把概率推向极端值,0.93 就够了
- 非正确类别也分到小概率,模型不会"完全不屑一顾"
- logits 不会过度膨胀,泛化能力提升
直觉:告诉模型"猫的图片也不一定 100% 是猫",符合标注不确定性。
8.4 三种正则化对比
| 方法 |
作用对象 |
核心思想 |
大模型使用 |
| Weight Decay |
参数 |
惩罚大权重,让模型更平滑 |
是(AdamW) |
| Dropout |
神经元 |
随机失活,防止共适应 |
部分使用 |
| Label Smoothing |
标签 |
软化标签,防止过度自信 |
是 |
9. 参数初始化
9.1 对称性问题
如果所有权重初始化为同一个值(如 w=0.01),同一层的所有神经元输出完全相同,反向传播时收到相同的梯度,更新后仍然相同——等价于只有 1 个神经元,网络表达能力严重浪费。
原则:权重必须随机初始化,打破对称性。
9.2 随机初始化的范围
权重不能太大也不能太小:
- w 太大 → 输出层层放大 → 梯度爆炸
- w 太小 → 输出层层缩小 → 梯度消失
9.3 Xavier 初始化
假设一层有 n 个输入,每个输入方差 σx2,权重方差 σw2,相互独立:
Var(z)=n⋅σx2⋅σw2
希望 Var(z)=σx2(输出方差 = 输入方差),解得:
σw2=n1
权重从 N(0,1/n) 的分布中采样。Xavier 假设激活函数是线性的。
9.4 Kaiming 初始化
ReLU 会把负半轴置零,输出方差减半。Kaiming 针对 ReLU 修正:
σw2=n2
权重从 N(0,2/n) 的分布中采样。
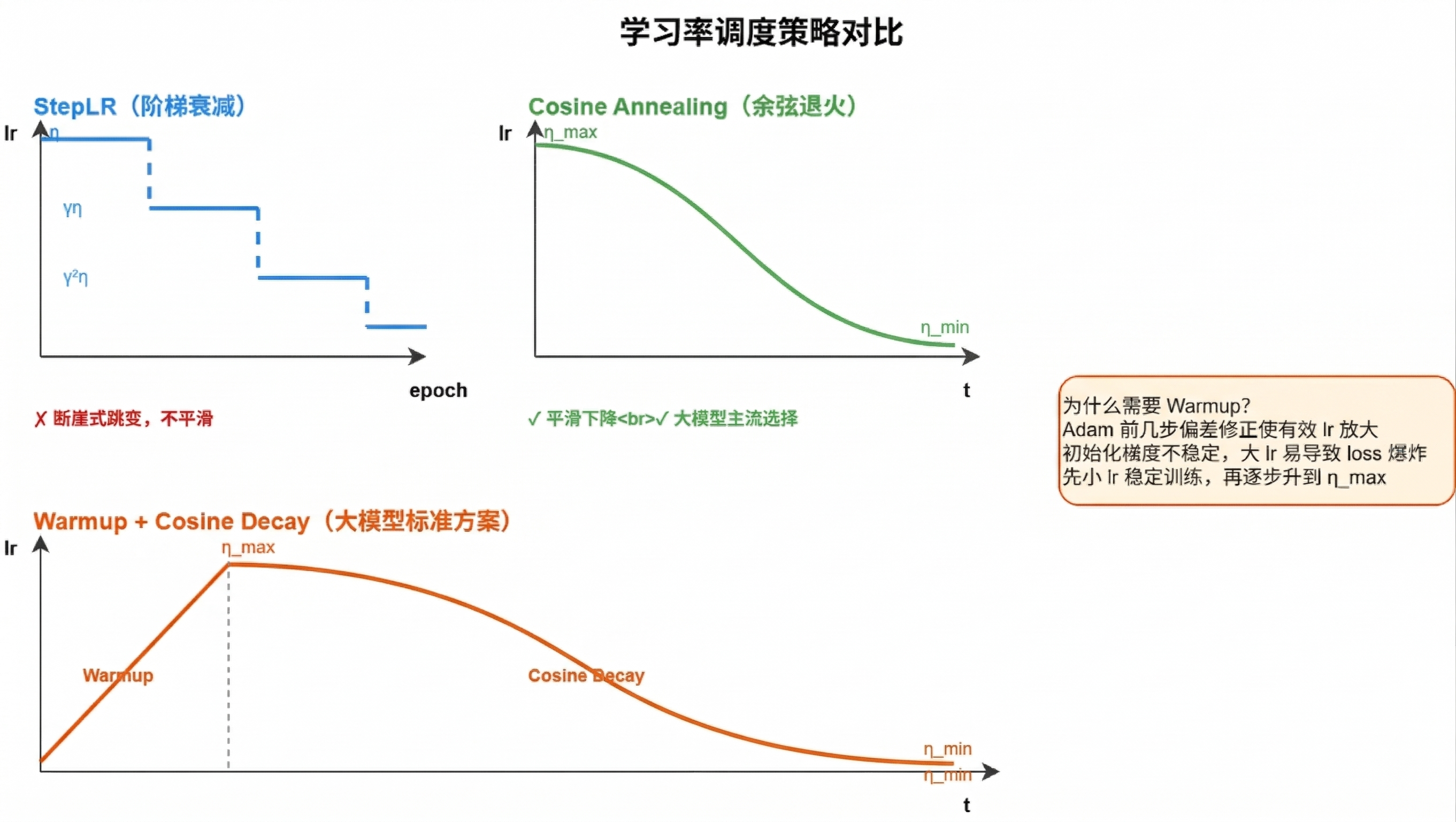
10. 学习率调度
10.1 为什么需要学习率调度
训练初期离最优解远 → 需要大步子快速逼近;后期接近最优解 → 需要小步子精细调整,否则在最优点附近震荡。全局学习率 η 应随训练过程递减。
10.2 StepLR(阶梯衰减)
每隔固定 epoch 数,学习率乘以衰减因子 γ(如 0.1):
ηt=η0⋅γ⌊t/T⌋
缺陷:断崖式下跌,衰减瞬间步子突然变小,两次衰减之间完全不变,不够平滑。
10.3 Cosine Annealing(余弦退火)
η(t)=ηmin+2ηmax−ηmin(1+cos(Tπt))
学习率沿余弦曲线从 ηmax 平滑下降到 ηmin,前期快后期慢。
优势:全程平滑收敛。大模型训练的主流选择(LLaMA、GPT 等都用它)。
10.4 Warmup + Cosine Decay(大模型标准方案)
完整的学习率曲线分三个阶段:
- Warmup 阶段(前几百~几千步):η 从 0 线性增长到 ηmax
- Cosine 衰减阶段:η 沿余弦曲线从 ηmax 平滑下降到 ηmin
- ηmin 阶段:保持很小的学习率做微调
为什么需要 Warmup:
- Adam 的偏差修正在前几步会使有效学习率放大(t=1 时 m^=m/0.1,放大 10 倍)
- 初始化阶段梯度方向不稳定,大 η 易导致 loss 爆炸
- 先小 η 稳定训练,等统计量积累好了再升到 ηmax
LLaMA 典型配置:ηmax=3×10−4,ηmin=ηmax×10%,warmup 占总步数 3%。
11. 概念关系总结
整个深度学习基础知识体系的逻辑链条:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| 线性模型 + 损失函数 → 定义"优化什么"
↓
梯度下降 + 反向传播 → 定义"怎么优化"
↓
┌────┴────┐
↓ ↓
Mini-batch 梯度消失/爆炸(深层网络核心问题)
↓
┌────────┼────────┐
↓ ↓ ↓
归一化 激活函数 参数初始化
(稳定输出) (稳定梯度) (稳定初始)
↓
固定 lr → 优化器演进 → AdamW(大模型标准)
↓
过拟合 → 正则化(Weight Decay + Dropout + Label Smoothing)
↓
训练不稳定 → 学习率调度(Warmup + Cosine Decay)
|
12. 数学符号汇总
| 符号 |
含义 |
| w |
权重(weight) |
| b |
偏置(bias) |
| x |
输入 |
| y^ |
预测值 |
| y |
真实值/标签 |
| L |
损失函数 |
| η |
学习率(learning rate) |
| g |
梯度 ∂L/∂w |
| m |
Adam 的一阶矩(梯度的指数移动平均) |
| v |
Adam 的二阶矩(梯度平方的指数移动平均) |
| β1,β2 |
Adam 一阶/二阶矩的衰减率(默认 0.9 / 0.999) |
| ϵ |
防除零的小常数(通常 10−8) |
| λ |
权重衰减系数 |
| p |
Dropout 丢弃概率 / 概率分布 |
| ε |
Label Smoothing 平滑系数 |
| σw2 |
权重初始化方差 |
| γ |
归一化的缩放参数 / 学习率衰减因子 |
| Φ(z) |
标准正态分布的 CDF |
| ⊙ |
逐元素相乘(Hadamard积) |
| H(p) |
信息熵 |
| DKL(p∥q) |
KL 散度 |