强化学习基本概念
目录
1. 核心术语
1.1 状态 (State, st)
状态是对环境的完整描述,包含了智能体在当前时刻所感知到的所有信息。在游戏场景中,状态通常是当前的游戏画面帧。
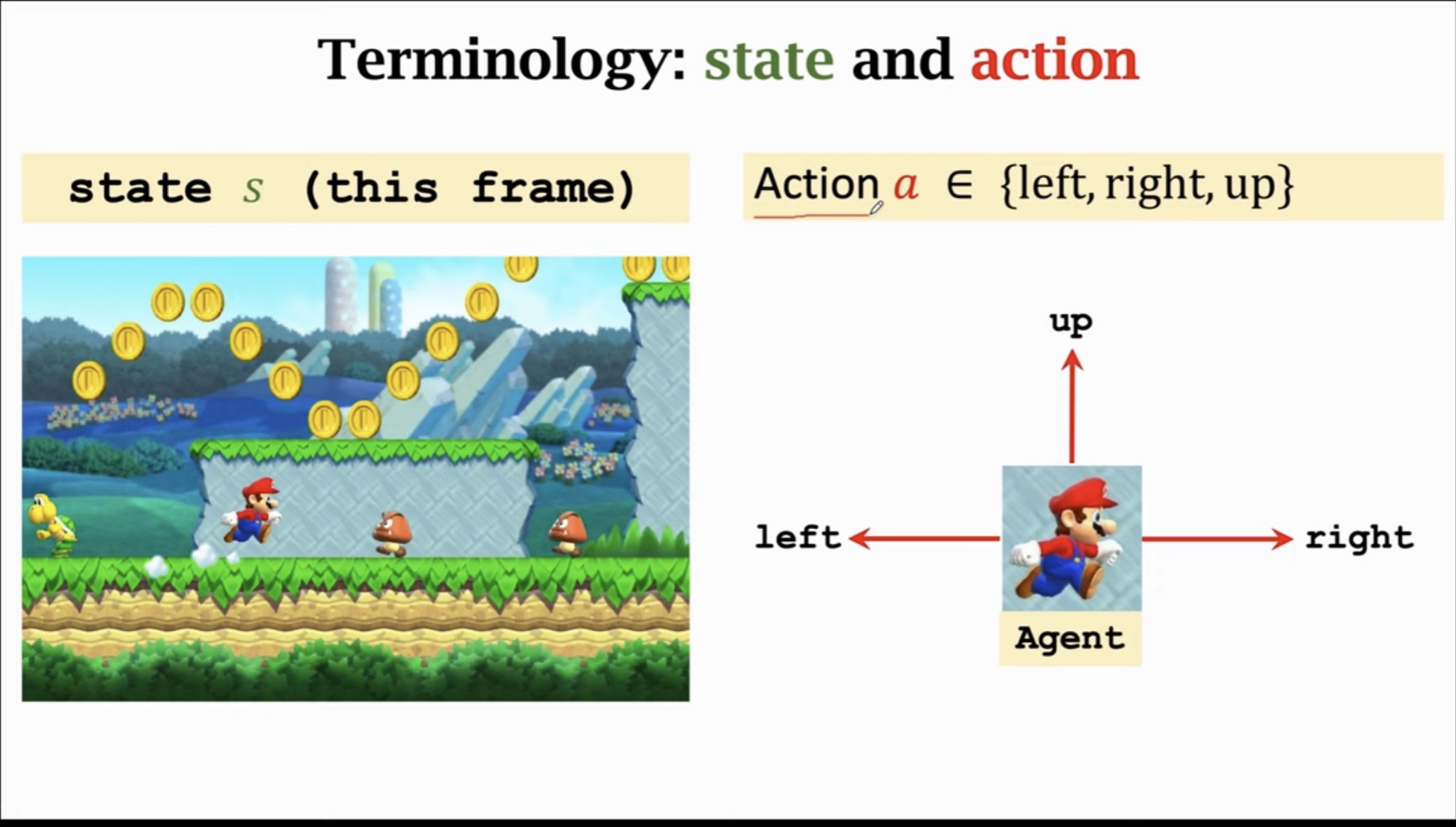
1.2 动作 (Action, at)
动作是智能体在某个状态下可以采取的行为。动作空间可以是离散的(如上下左右),也可以是连续的(如控制机械臂的角度)。
at∈{left,right,up}
1.3 奖励 (Reward, rt)
奖励是环境对智能体在时刻 t 采取动作 at 后的反馈,是一个标量值。正奖励表示好的结果,负奖励表示坏的结果。
2. Agent与环境交互
强化学习的核心是 智能体(Agent) 与 环境(Environment) 之间的交互循环:
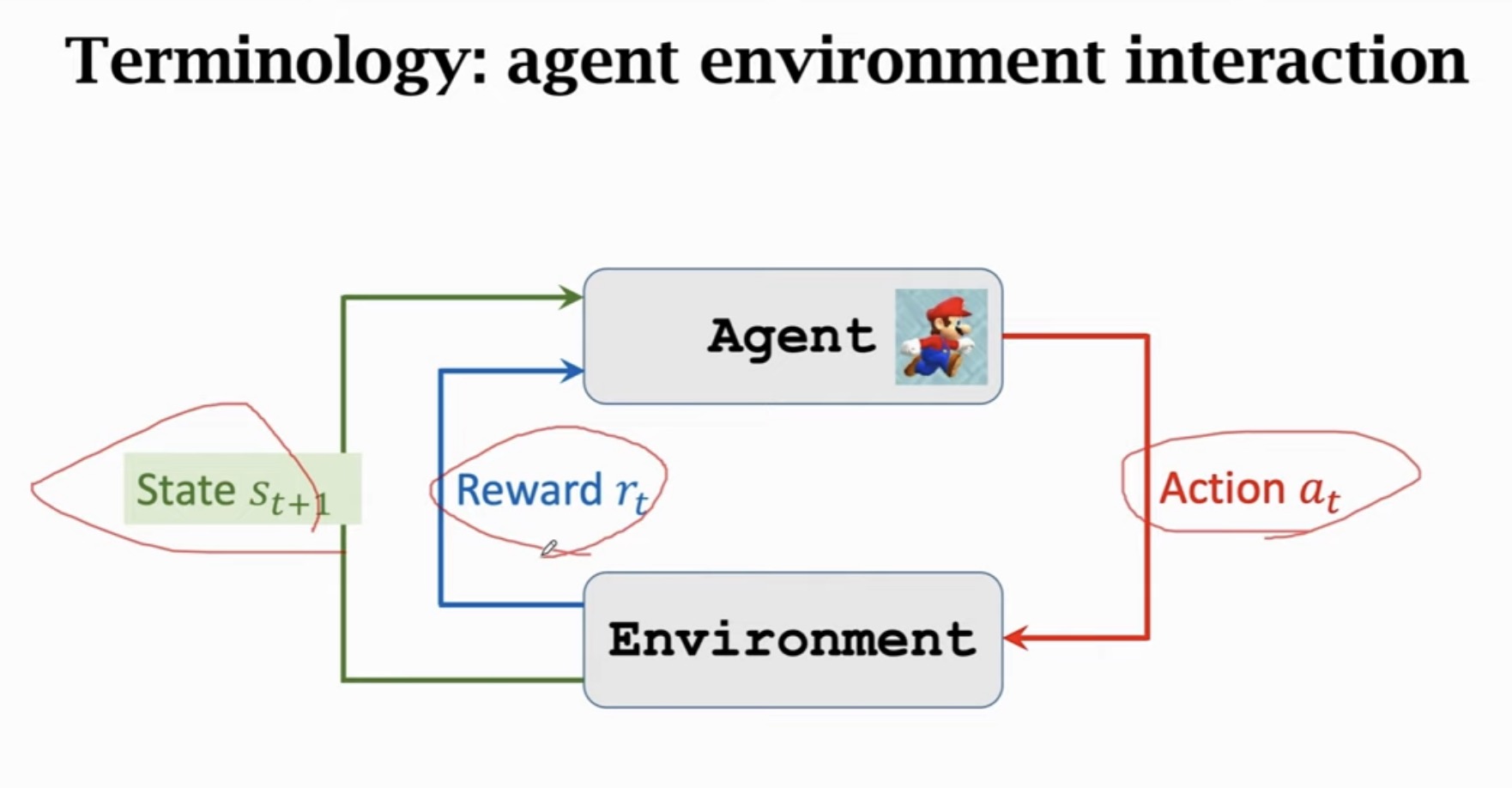
2.1 交互流程
在每个时间步 t:
- 智能体观察当前状态 St=st
- 智能体选择并执行动作 At=at
- 环境转移到新状态 St+1=st+1
- 环境给出奖励 Rt=rt
2.2 完整轨迹
使用AI玩游戏时的完整交互过程形成一个轨迹:
s1,a1,r1,s2,a2,r2,⋯,sT,aT,rT

3. 策略 Policy
3.1 策略的定义
策略 π 是一个从状态到动作概率分布的映射函数:
π:(s,a)↦[0,1]
π(a∣s)=P(A=a∣S=s)
策略表示在给定状态 s 时,智能体选择动作 a 的概率。
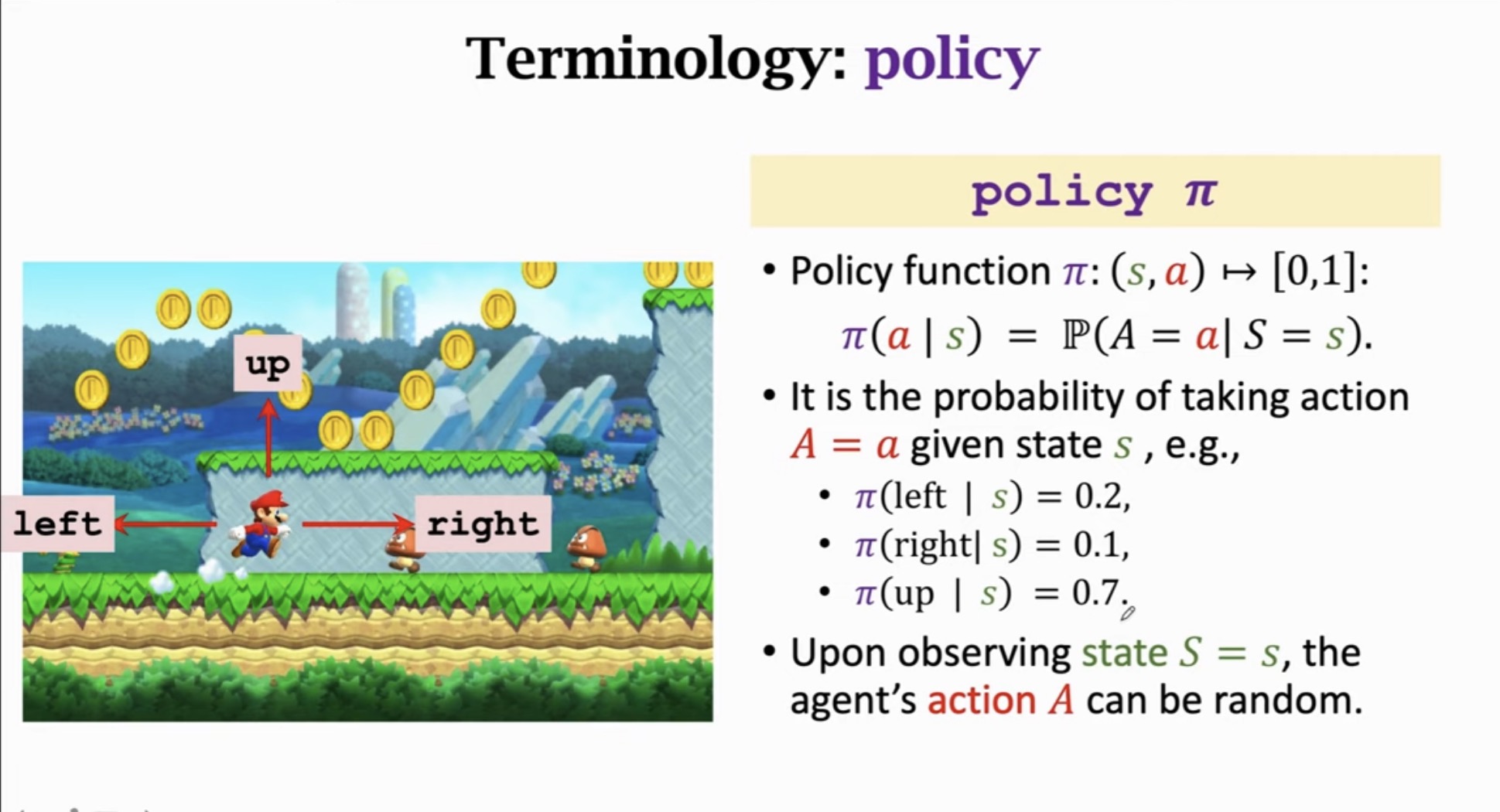
3.2 策略示例
在某个状态 s 下,策略可能为:
π(left∣s)π(right∣s)π(up∣s)=0.2=0.1=0.7
这意味着智能体有70%的概率选择向上移动,20%向左,10%向右。
4. 状态转移
4.1 状态转移概率
给定当前状态 s 和动作 a,环境会根据一定的概率转移到下一个状态 s′。这个过程描述了环境的动力学:
p(s′∣s,a)=P(S′=s′∣S=s,A=a)
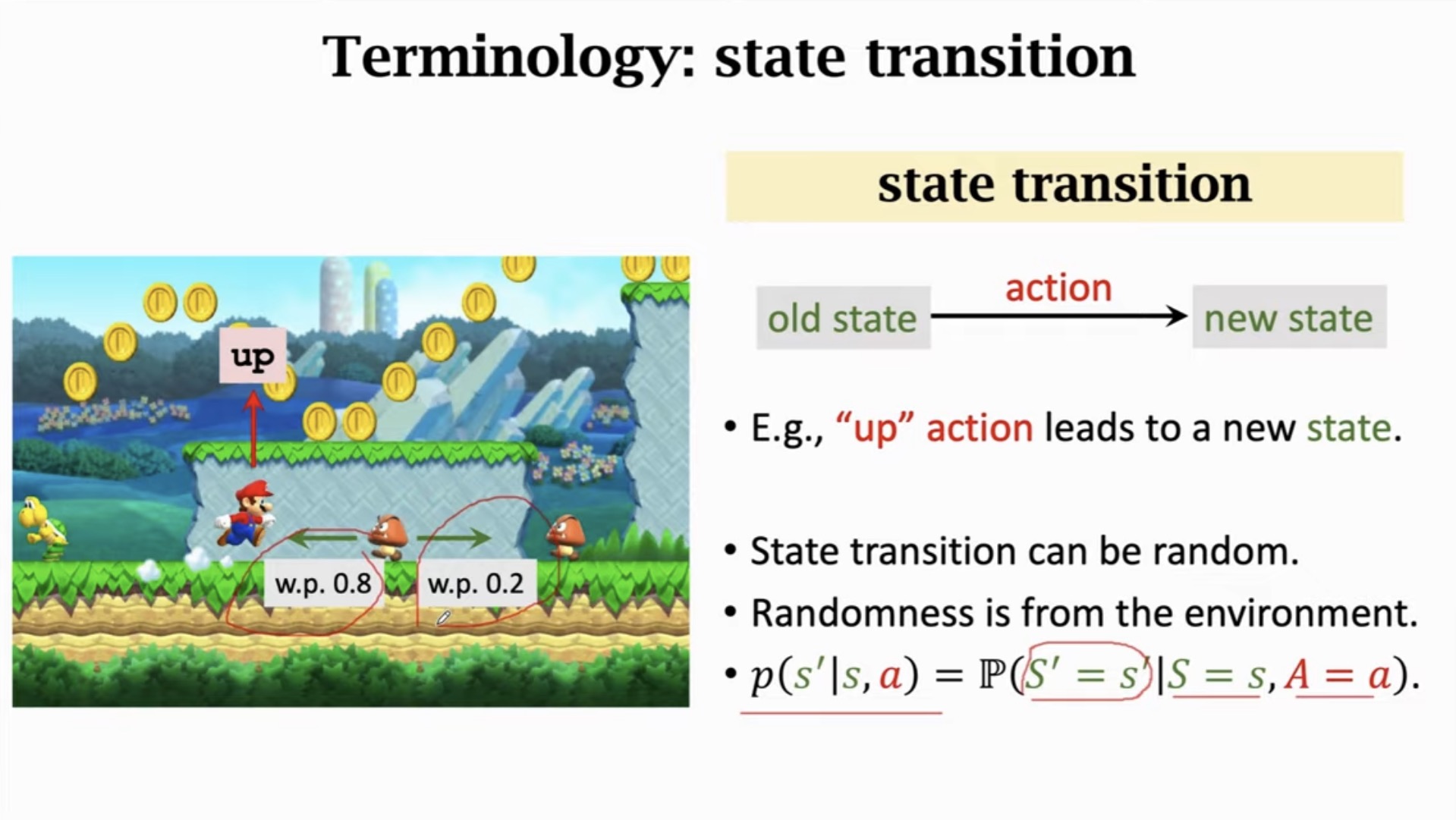
4.2 强化学习中的随机性
强化学习中存在两种主要的随机性:
- 动作的随机性:来自策略 π(a∣s)
- 状态转移的随机性:来自环境的转移概率 p(s′∣s,a)

5. 回报 Return
5.1 回报的定义
回报 Ut 是从时刻 t 开始到未来所有奖励的累积和:
Ut=Rt+Rt+1+Rt+2+Rt+3+⋯
5.2 折扣回报
由于未来奖励的不确定性,我们引入折扣因子 γ(0≤γ≤1)来对远期奖励进行打折:
Ut=Rt+γRt+1+γ2Rt+2+γ3Rt+3+⋯=i=0∑∞γiRt+i

折扣因子的作用:
- γ 接近 1:更关注长期奖励
- γ 接近 0:更关注即时奖励
5.3 回报的随机性
在时刻 t,回报 Ut 是一个随机变量,其随机性来源于:
- 动作的随机性:At,At+1,At+2,…
- 状态转移的随机性:St+1,St+2,…

对于任意 i≥t,奖励 Ri 依赖于 Si 和 Ai。
6. 价值函数
价值函数用于评估状态或状态-动作对的好坏程度。
6.1 动作价值函数 (Action-Value Function, Qπ)
Qπ(st,at)=E[Ut∣St=st,At=at]
含义:在策略 π 下,从状态 st 采取动作 at 开始,未来期望回报是多少。
用途:评估在特定状态下采取特定动作的好坏程度。
6.2 状态价值函数 (State-Value Function, Vπ)
Vπ(s)=EA[Qπ(s,A)]=a∑π(a∣s)⋅Qπ(s,a)
含义:在策略 π 下,从状态 s 开始(按策略选择动作),未来期望回报是多少。
用途:评估某个状态本身的优劣。
6.3 策略评估
要评估整个策略 π 的好坏,可以计算状态价值的期望:
ES[Vπ(S)]=s∑p(s)⋅Vπ(s)
其中 p(s) 是访问状态 s 的概率分布。

7. 智能体控制
在实际应用中,有两种主要方式来控制智能体:
7.1 基于策略的控制
如果我们有一个好的策略 π(a∣s),控制方式为:
1
2
| 观察状态 s_t
随机采样:a_t ~ π(·|s_t)
|
智能体根据策略的概率分布随机选择动作。
7.2 基于价值函数的控制
如果我们知道最优动作价值函数 Q∗(s,a),控制方式为:
1
2
| 观察状态 s_t
选择价值最大的动作:a_t = argmax_a Q*(s_t, a)
|
智能体贪婪地选择当前状态下价值最高的动作。

概念关系总结
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| ┌─────────────────────────────────────────────────────────┐
│ 强化学习基本框架 │
├─────────────────────────────────────────────────────────┤
│ │
│ ┌─────────┐ 动作 At ┌─────────────┐ │
│ │ Agent │ ────────────→ │ Environment │ │
│ │ │ │ │ │
│ └─────────┘ ←──────────── └─────────────┘ │
│ ↑ 状态 St+1 奖励 Rt │
│ │ │
│ 策略 π(a|s) │
│ │ │
│ ↓ │
│ ┌──────────────────────────────────────┐ │
│ │ 价值函数 │ │
│ │ • Qπ(s,a): 动作价值 │ │
│ │ • Vπ(s): 状态价值 │ │
│ └──────────────────────────────────────┘ │
│ │
│ 优化目标: 最大化期望回报 E[Ut] │
│ │
└─────────────────────────────────────────────────────────┘
|
数学符号汇总
| 符号 |
含义 |
| St,st |
时刻t 的状态 |
| At,at |
时刻t 的动作 |
| Rt,rt |
时刻t 的奖励 |
| π(a∥s) |
策略函数 |
| p(s′∥s,a) |
状态转移概率 |
| γ |
折扣因子 |
| Ut |
时刻t 的回报 |
| Qπ(s,a) |
动作价值函数 |
| Vπ(s) |
状态价值函数 |
| Q∗(s,a) |
最优动作价值函数 |