基于价值的强化学习 (Value-Based Reinforcement Learning)
目录
1. Q函数近似问题
1.1 目标
强化学习的最终目标是赢得游戏(等价于最大化总奖励)。
1.2 最优动作
如果我们知道最优动作价值函数 Q∗(s,a),那么在状态 s 下的最佳动作就是:
a∗=argamaxQ∗(s,a)
这意味着我们应该选择使Q值最大的动作。

1.3 核心挑战
问题:我们实际上不知道 Q∗(s,a)
在复杂的游戏环境中(如 Atari 游戏或 Go),状态空间和动作空间都非常庞大,无法用表格形式存储所有的 Q(s,a) 值。
1.4 解决方案:深度Q网络
核心思想:使用神经网络来近似 Q∗(s,a)
Q(s,a;w)≈Q∗(s,a)
其中 w 是神经网络的参数(权重)。
2. 深度Q网络 (DQN)
2.1 网络架构
DQN 是一个神经网络,用于将状态映射到每个动作的Q值:
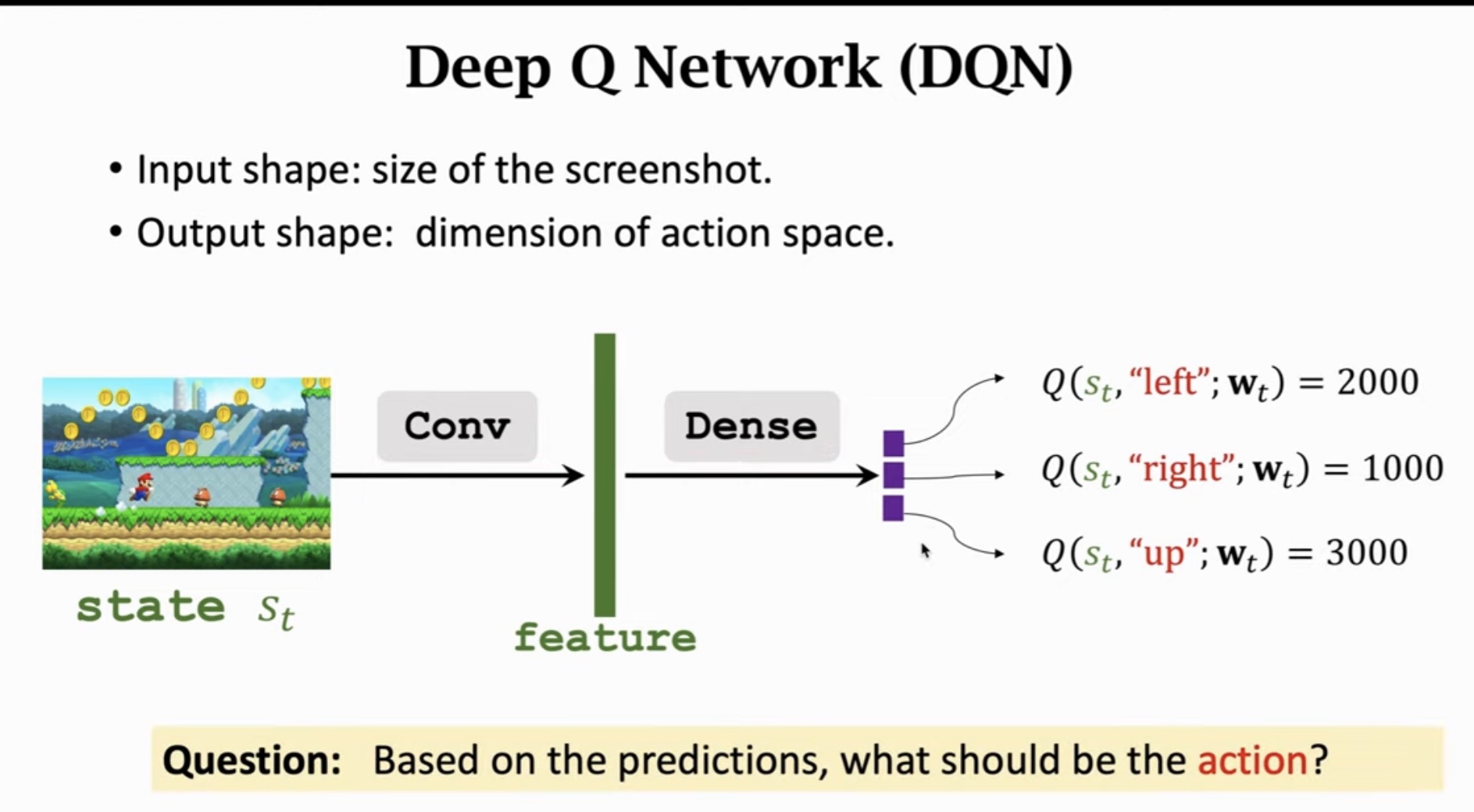
输入层:游戏截图的像素值
- 输入形状:
(height, width, channels)
- 例如:
(84, 84, 4) 表示4帧堆叠的灰度图像
卷积层 (Conv):提取视觉特征
全连接层 (Dense):输出动作价值
2.2 数学表示
Q(st,a;wt)=fNN(st;wt)[a]
其中 fNN 是神经网络的前向传播函数,[a] 表示取动作 a 对应的输出。
2.3 示例
假设动作空间为 {left,right,up}:
Q(st,"left";wt)Q(st,"right";wt)Q(st,"up";wt)=2000=1000=3000
问题:基于以上预测,应该选择什么动作?
答案:选择 "up",因为 3000=max{2000,1000,3000}
3. DQN在游戏中的应用
3.1 决策流程
使用DQN玩游戏时,每个时间步的决策过程如下:

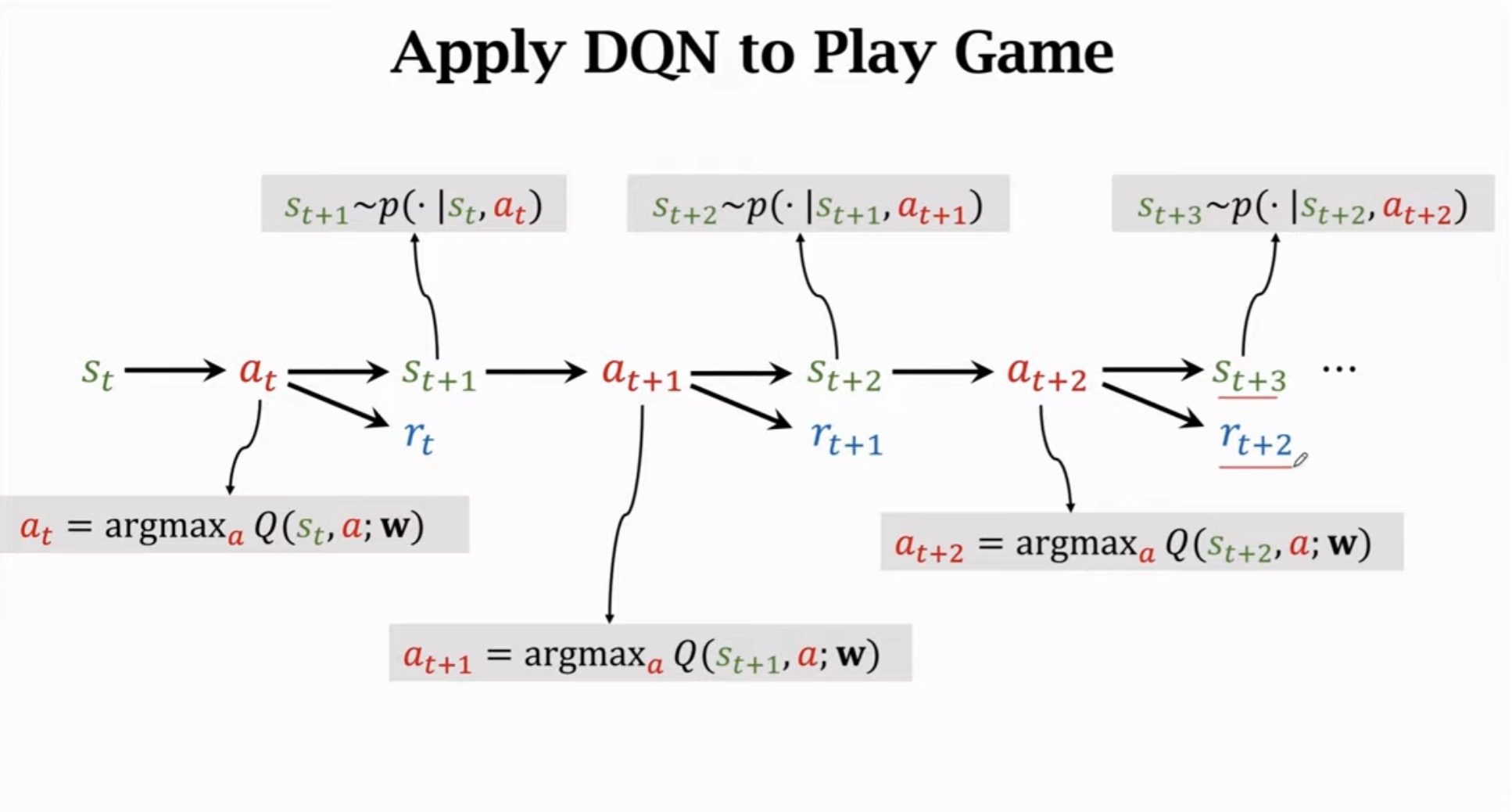
3.2 状态-动作-奖励序列
完整的交互过程形成一条轨迹:
statst+1at+1st+2at+2st+3at+3⋯
对应的奖励序列:
rt,rt+1,rt+2,⋯
3.3 动作选择策略
在每个状态 st,智能体选择动作:
at=argamaxQ(st,a;wt)
这是一种贪婪策略(greedy policy),即总是选择当前估计价值最高的动作。
3.4 环境动力学
状态转移遵循环境的动力学模型:
st+1∼p(⋅∣st,at)
st+2∼p(⋅∣st+1,at+1)
st+3∼p(⋅∣st+2,at+2)
其中 p(s′∣s,a) 是状态转移概率函数。
4. 时序差分学习 (TD Learning)
4.1 TD学习概述
时序差分学习 (Temporal Difference Learning) 是强化学习中用于学习价值函数的核心方法。它结合了蒙特卡洛方法和动态规划的优点。
4.2 TD学习算法
一次TD学习的迭代包含以下6个步骤:
步骤1:观察状态和动作
St=st,At=at
步骤2:预测Q值
qt=Q(st,at;wt)
这是神经网络对当前状态-动作对价值的估计。
步骤3:计算梯度
dt=∂w∂Q(st,at;w)∣∣∣∣w=wt
这是Q函数关于网络参数的梯度,用于后续的梯度更新。
步骤4:环境反馈
环境提供新的状态 st+1 和奖励 rt
步骤5:计算TD目标
yt=rt+γ⋅amaxQ(st+1,a;wt)
TD目标由两部分组成:
- 即时奖励 rt:当前动作的立即反馈
- 折扣未来价值 γ⋅maxaQ(st+1,a;wt):下一状态的最大Q值
步骤6:梯度下降更新
wt+1=wt−α⋅(qt−yt)⋅dt
参数解释:
- α:学习率 (learning rate)
- qt−yt:TD误差 (TD error)
- dt:梯度方向
4.3 TD误差
δt=qt−yt=Q(st,at;wt)−[rt+γ⋅amaxQ(st+1,a;wt)]
TD误差反映了我们的估计与目标之间的差距。我们的目标是最小化这个误差。
4.4 损失函数
从优化的角度看,TD学习最小化以下损失函数:
L(w)=Est,at,rt,st+1[(Q(st,at;w)−(rt+γ⋅amaxQ(st+1,a;w)))2]
这是Bellman误差的期望平方。
5. 完整算法流程
5.1 DQN训练算法
1
2
3
4
5
6
7
8
9
10
11
12
| 初始化:Q网络参数 w,回放缓冲区 D
对于每个回合 episode:
初始化状态 s_t
对于每个时间步 t:
1. 选择动作:a_t = argmax_a Q(s_t, a; w) + 探索噪声
2. 执行动作,获得奖励 r_t 和新状态 s_{t+1}
3. 存储经验:(s_t, a_t, r_t, s_{t+1}) → D
4. 从 D 中随机采样一个小批量
5. 对每个样本计算 TD 目标:y = r + γ·max_a' Q(s', a'; w)
6. 计算损失:L = (Q(s, a; w) - y)²
7. 梯度下降更新:w ← w - α·∇_w L
8. s_t ← s_{t+1}
|
5.2 关键技术创新
实际应用中,DQN通常包含以下改进:
经验回放 (Experience Replay)
- 将经验 (st,at,rt,st+1) 存储在缓冲区
- 随机采样进行训练,打破数据相关性
目标网络 (Target Network)
- 使用独立的目标网络 Q(s,a;w−) 计算TD目标
- 定期将主网络参数复制到目标网络
- 提高训练稳定性
yt=rt+γ⋅amaxQ(st+1,a;wt−)
ε-贪婪探索 (ε-greedy Exploration)
at={argmaxaQ(st,a;w)随机动作以概率 1−ϵ以概率 ϵ
概念关系总结
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| ┌─────────────────────────────────────────────────────────────┐
│ 基于价值的强化学习 (Value-Based RL) │
├─────────────────────────────────────────────────────────────┤
│ │
│ 目标:学习 Q*(s,a) → 选择最优动作 a* = argmax_a Q*(s,a) │
│ │
│ 挑战:Q*(s,a) 未知 → 用神经网络 Q(s,a;w) 近似 │
│ ↓ │
│ ┌─────────────────────────────────────────────┐ │
│ │ Deep Q-Network (DQN) │ │
│ │ ┌─────────┐ ┌──────────┐ ┌────────┐ │ │
│ │ │ 图像输入 │ → │ Conv+Dense│ → │ Q-values│ │ │
│ │ └─────────┘ └──────────┘ └────────┘ │ │
│ └─────────────────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────────────────┐ │
│ │ Temporal Difference (TD) Learning │ │
│ │ │ │
│ │ TD目标: y_t = r_t + γ·max_a Q(s_{t+1},a) │ │
│ │ 更新: w ← w - α·(Q - y)·∇_w Q │ │
│ └─────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘
|
数学符号汇总
| 符号 |
含义 |
| Q∗(s,a) |
最优动作价值函数 |
| Q(s,a;w) |
神经网络近似的Q函数 |
| w |
神经网络参数 |
| st |
时刻t 的状态 |
| at |
时刻t 的动作 |
| rt |
时刻t 的奖励 |
| γ |
折扣因子 |
| α |
学习率 |
| yt |
TD目标 |
| δt |
TD误差 |
| dt |
Q函数梯度 |
| p(s′∥s,a) |
状态转移概率 |
| ϵ |
探索率 |
核心公式速查
1. 动作选择
at=argamaxQ(st,a;wt)
2. TD目标
yt=rt+γ⋅amaxQ(st+1,a;wt)
3. TD误差
δt=Q(st,at;wt)−yt
4. 参数更新
wt+1=wt−α⋅δt⋅∇wQ(st,at;wt)
5. 损失函数
L(w)=E[(Q(s,a;w)−(r+γ⋅amaxQ(s′,a;w)))2]
参考文献
本笔记基于强化学习课程的基于价值方法部分,涵盖了DQN架构、时序差分学习等核心内容。相关经典论文:
- Mnih et al. (2015). “Human-level control through deep reinforcement learning”. Nature.
- Watkins & Dayan (1992). “Q-learning”. Machine Learning.