基于策略的强化学习 (Policy-Based Reinforcement Learning)
目录
1. 策略网络
1.1 核心思想
策略网络 (Policy Network) 是一个神经网络,用于直接参数化策略函数 π(a∣s)。
π(a∣s)≈π(a∣s;θ)
其中 θ 是神经网络的可训练参数。
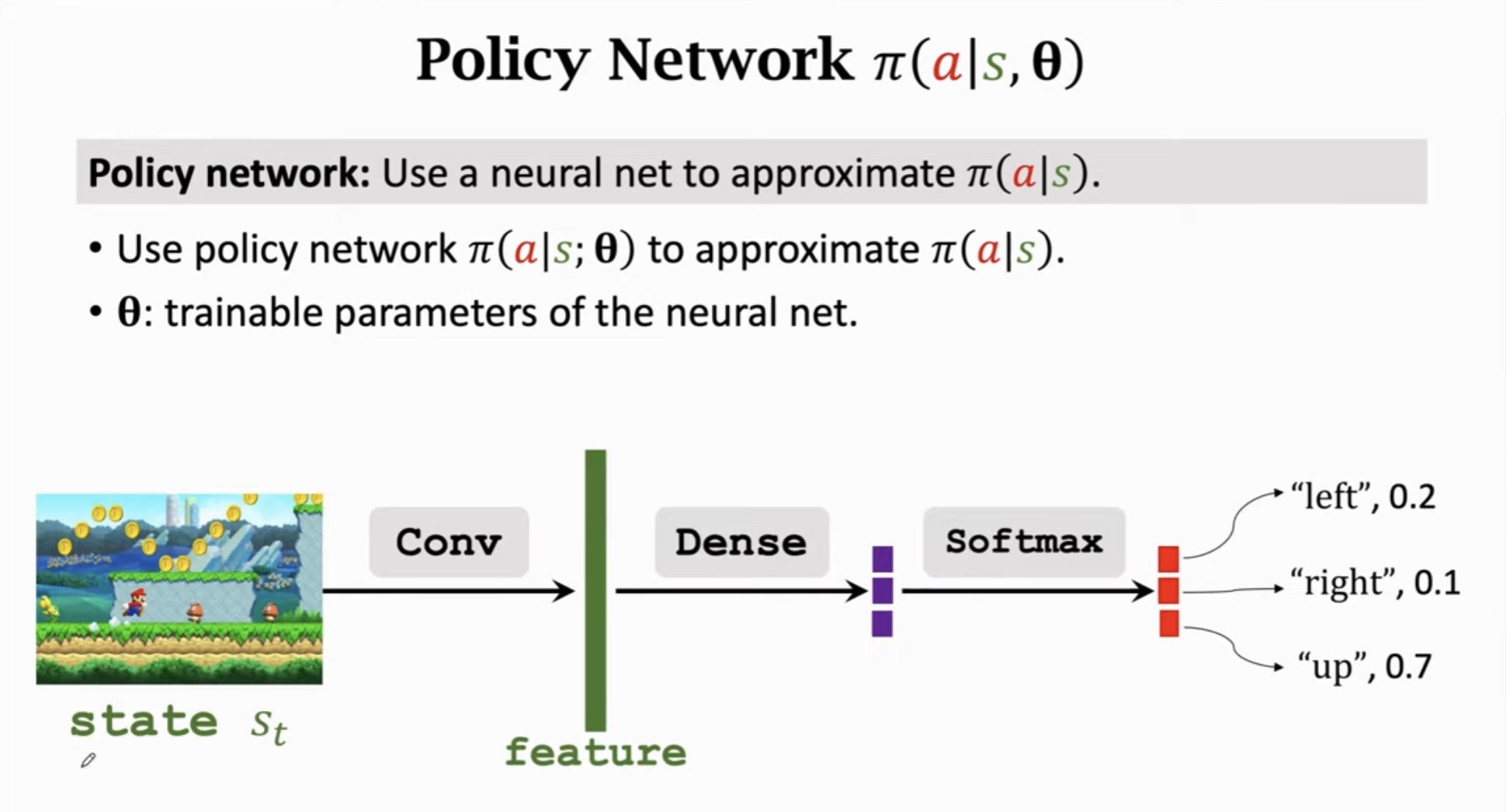
1.2 网络架构
策略网络通常包含以下层次:
1
2
3
4
5
6
7
8
9
| 状态 S_t (图像)
↓
卷积层 (Conv) → 提取特征
↓
全连接层 (Dense)
↓
Softmax层 → 输出概率分布
↓
动作概率: {"left": 0.2, "right": 0.1, "up": 0.7}
|
1.3 Softmax输出
策略网络的输出是一个概率分布,所有动作概率之和为1:
a∈A∑π(a∣s;θ)=1
2. 状态价值函数近似
2.1 状态价值函数定义
在强化学习中,状态价值函数 Vπ(s) 表示在策略 π 下,从状态 s 开始的期望回报:
Vπ(st)=EA[Qπ(st,A)]=a∑π(a∣st)⋅Qπ(st,a)
这个公式表明:状态价值等于该状态下所有动作价值的期望。

2.2 近似状态价值函数
使用策略网络 π(a∣s;θ) 近似策略函数后,状态价值函数也相应变为:
V(s;θ)=a∑π(a∣s;θ)⋅Qπ(s,a)
关键区别:
- Vπ(s):真实的状态价值(使用真实策略)
- V(s;θ):近似的状态价值(使用参数化策略)
2.3 目标函数
基于策略的强化学习的目标是找到最优参数 θ,使得期望状态价值最大化:
J(θ)=ES[V(S;θ)]=s∑p(s)⋅V(s;θ)
其中 p(s) 是访问状态 s 的概率分布。
3. 策略梯度上升
3.1 优化问题
我们的目标是最大化目标函数 J(θ):
θ∗=argθmaxJ(θ)=argθmaxES[V(S;θ)]
3.2 梯度上升法
使用梯度上升 (Gradient Ascent) 来优化参数:
θ←θ+β⋅∂θ∂V(s;θ)
其中:
- β:学习率 (learning rate)
- ∂θ∂V(s;θ):策略梯度 (policy gradient)

3.3 为什么是梯度上升?
因为我们想要最大化目标函数 J(θ),所以使用梯度上升(沿着梯度方向更新参数),而不是梯度下降。
4. 策略梯度推导
4.1 策略梯度定义
策略梯度是状态价值函数关于参数 θ 的导数:
∂θ∂V(s;θ)
4.2 数学推导
从状态价值函数的定义出发:
V(s;θ)=a∑π(a∣s;θ)⋅Qπ(s,a)
对 θ 求导(使用乘积法则):
∂θ∂V(s;θ)=a∑∂θ∂π(a∣s;θ)⋅Qπ(s,a)
4.3 对数导数技巧
利用恒等式 ∂θ∂π=π⋅∂θ∂logπ:
∂θ∂V(s;θ)=a∑π(a∣s;θ)⋅∂θ∂logπ(a∣s;θ)⋅Qπ(s,a)=EA[∂θ∂logπ(A∣s;θ)⋅Qπ(s,A)]

4.4 策略梯度的两种形式
形式1(直接求和形式):
∂θ∂V(s;θ)=a∑∂θ∂π(a∣s;θ)⋅Qπ(s,a)
形式2(期望形式):
∂θ∂V(s;θ)=EA[∂θ∂logπ(A∣s;θ)⋅Qπ(s,A)]
注意:上述推导是简化版本,严格推导需要更复杂的数学处理。
5. 离散动作的策略梯度计算
5.1 适用场景
当动作空间是离散的时,例如:
A={"left","right","up"}
5.2 使用形式1
对于离散动作空间,我们可以使用直接求和形式:
∂θ∂V(s;θ)=a∑∂θ∂π(a∣s;θ)⋅Qπ(s,a)
5.3 计算步骤
步骤1:对每个动作计算 f(a,θ)
f(a,θ)=∂θ∂π(a∣s;θ)⋅Qπ(s,a),∀a∈A
步骤2:对所有动作求和
∂θ∂V(s;θ)=f("left",θ)+f("right",θ)+f("up",θ)

5.4 局限性
这种方法不适用于连续动作空间,因为无法对无限多个动作求和。
6. 连续动作的策略梯度计算
6.1 适用场景
当动作空间是连续的时,例如:
A=[0,1]
6.2 使用形式2
对于连续动作空间,我们使用期望形式:
∂θ∂V(s;θ)=EA∼π(⋅∣s;θ)[∂θ∂logπ(A∣s,θ)⋅Qπ(s,A)]
6.3 蒙特卡洛近似
由于期望无法精确计算,我们使用采样来近似:
步骤1:根据策略 π(⋅∣s;θ) 随机采样一个动作 a^
步骤2:计算梯度估计
g(a^,θ)=∂θ∂logπ(a^∣s;θ)⋅Qπ(s,a^)
步骤3:使用 g(a^,θ) 作为策略梯度的近似
∂θ∂V(s;θ)≈g(a^,θ)

6.4 通用性
重要说明:这种方法也适用于离散动作空间!
因此,形式2(期望形式)是更通用的策略梯度计算方法。
7. 完整算法
基于策略梯度的强化学习完整算法如下:
7.1 算法步骤
步骤1:观察当前状态 St
步骤2:根据策略 π(⋅∣St;θt) 随机采样动作 at
at∼π(⋅∣St;θt)
步骤3:计算 qt≈Qπ(St,at)(某个估计值)
步骤4:计算策略网络的对数梯度
dθ,t=∂θ∂logπ(at∣St,θ)∣∣∣∣θ=θt
步骤5:计算(近似)策略梯度
g(at,θt)=qt⋅dθ,t
步骤6:更新策略网络参数
θt+1=θt+β⋅g(at,θt)

7.2 算法流程图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| ┌─────────────────────────────────────────────────────────┐
│ 策略梯度算法 │
├─────────────────────────────────────────────────────────┤
│ │
│ 观察状态 S_t │
│ ↓ │
│ 采样动作 a_t ~ π(·|S_t; θ_t) │
│ ↓ │
│ 计算 q_t ≈ Q_π(S_t, a_t) │
│ ↓ │
│ 计算对数梯度 d_θ,t = ∂log π/∂θ │
│ ↓ │
│ 计算策略梯度 g = q_t · d_θ,t │
│ ↓ │
│ 更新参数 θ_{t+1} = θ_t + β · g │
│ ↓ │
│ 返回开始,继续下一时间步 │
│ │
└─────────────────────────────────────────────────────────┘
|
8. Q值估计方法
算法中的关键步骤是步骤3:如何估计 qt≈Qπ(st,at)?
8.1 方法1:REINFORCE(蒙特卡洛策略梯度)
核心思想:玩完整局游戏,使用实际回报作为Q值的估计。

步骤1:生成完整轨迹
玩游戏直到结束,生成完整轨迹:
s1,a1,r1,s2,a2,r2,…,sT,aT,rT
步骤2:计算折扣回报
对每个时间步 t,计算折扣回报:
ut=k=t∑Tγk−trk
其中 γ∈[0,1] 是折扣因子。
步骤3:使用回报作为Q值估计
由于 Qπ(st,at)=E[Ut],我们可以用 ut 来近似 Qπ(st,at):
qt=ut
REINFORCE的优缺点
优点:
- 无偏估计(unbiased estimator)
- 不需要学习价值函数
缺点:
- 必须等到episode结束才能更新
- 方差较大(high variance)
8.2 方法2:Actor-Critic(演员-评论家方法)
核心思想:使用神经网络来近似 Qπ。

方法描述
训练一个神经网络 Q^(s,a;ϕ) 来近似 Qπ(s,a):
Qπ(s,a)≈Q^(s,a;ϕ)
然后使用:
qt=Q^(st,at;ϕ)
Actor-Critic架构
- Actor(演员):策略网络 π(a∣s;θ),负责选择动作
- Critic(评论家):价值网络 Q^(s,a;ϕ),负责评估动作价值
Actor-Critic的优缺点
优点:
- 可以在每个时间步更新(不需要等episode结束)
- 方差较小(lower variance)
缺点:
- 有偏估计(biased estimator)
- 需要同时训练两个网络
概念关系总结
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| ┌─────────────────────────────────────────────────────────────┐
│ 基于策略的强化学习 (Policy-Based RL) │
├─────────────────────────────────────────────────────────────┤
│ │
│ 目标:最大化期望状态价值 J(θ) = E_S[V(S; θ)] │
│ │
│ 策略网络:π(a|s; θ) ≈ π(a|s) │
│ ↓ │
│ ┌─────────────────────────────────────────────┐ │
│ │ 策略梯度定理 │ │
│ │ │ │
│ │ ∂V(s;θ)/∂θ = E_A[∂log π(A|s;θ)/∂θ · Q_π] │ │
│ └─────────────────────────────────────────────┘ │
│ ↓ │
│ ┌──────────┬──────────────────────────────────┐ │
│ │ │ │ │
│ │ 离散动作 │ 连续动作 │ │
│ │ │ (通用,也适用于离散) │ │
│ │ │ │ │
│ │ 形式1: │ 形式2: │ │
│ │ 求和 │ 期望+采样 │ │
│ │ │ │ │
│ └──────────┴──────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────────────────┐ │
│ │ Q值估计方法 │ │
│ ├──────────────────┬──────────────────────────┤ │
│ │ REINFORCE │ Actor-Critic │ │
│ │ (蒙特卡洛) │ (价值网络近似) │ │
│ │ │ │ │
│ │ • 无偏估计 │ • 有偏估计 │ │
│ │ • 高方差 │ • 低方差 │ │
│ │ • episode结束 │ • 在线更新 │ │
│ └──────────────────┴──────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘
|
数学符号汇总
| 符号 |
含义 |
| π(a∥s;θ) |
参数化策略函数 |
| θ |
策略网络参数 |
| β |
学习率 |
| Vπ(s) |
策略 π 下的状态价值 |
| V(s;θ) |
近似状态价值 |
| Qπ(s,a) |
策略 π 下的动作价值 |
| J(θ) |
目标函数(期望状态价值) |
| ∂θ∂V |
策略梯度 |
| E[⋅] |
期望 |
| γ |
折扣因子 |
| ut |
折扣回报(REINFORCE中) |
| qt |
Q值估计 |
| A |
动作空间 |
| Q^(s,a;ϕ) |
Critic网络的Q值估计 |
核心公式速查
1. 状态价值函数
V(s;θ)=a∑π(a∣s;θ)⋅Qπ(s,a)
2. 目标函数
J(θ)=ES[V(S;θ)]
3. 策略梯度(形式1-离散动作)
∂θ∂V(s;θ)=a∑∂θ∂π(a∣s;θ)⋅Qπ(s,a)
4. 策略梯度(形式2-连续动作/通用)
∂θ∂V(s;θ)=EA[∂θ∂logπ(A∣s;θ)⋅Qπ(s,A)]
5. 参数更新
θt+1=θt+β⋅qt⋅∂θ∂logπ(at∣st;θt)
6. 折扣回报(REINFORCE)
ut=k=t∑Tγk−trk
基于价值 vs 基于策略
| 特性 |
基于价值 (DQN) |
基于策略 (Policy Gradient) |
| 学习内容 |
学习 Q(s,a) |
直接学习 π(a∥s;θ) |
| 动作选择 |
argmaxaQ(s,a) |
从 π(a∥s;θ) 采样 |
| 适用场景 |
离散动作 |
离散 + 连续动作 |
| 策略类型 |
确定性(贪婪) |
随机性(概率分布) |
| 收敛性 |
更稳定 |
可能收敛到局部最优 |
参考文献
本笔记基于强化学习课程的基于策略方法部分,涵盖了策略网络、策略梯度定理、REINFORCE算法和Actor-Critic方法等核心内容。相关经典论文:
- Williams (1992). “Simple statistical gradient-following algorithms for connectionist RL”. Machine Learning. (REINFORCE算法)
- Sutton et al. (2000). “Policy Gradient Methods for Reinforcement Learning with Function Approximation”. NIPS.
- Konda & Tsitsiklis (2000). “Actor-Critic Algorithms”. NIPS.