Actor-Critic 方法
目录
1. 核心思想
Actor-Critic 方法是基于策略的强化学习与基于价值的强化学习的结合体。它同时使用两个神经网络:
- Actor(演员):策略网络 π(a∣s;θ),负责选择动作
- Critic(评论家):价值网络 q(s,a;w),负责评估动作的好坏
Actor 和 Critic 互相配合——Actor 学习如何行动,Critic 学习如何评判;Actor 根据评判结果改进自己的策略。
为什么需要 Critic? 在纯策略梯度(如 REINFORCE)中,需要玩完整局游戏才能获得 Q 值估计,方差很大。Critic 提供了一个在线的、低方差的 Q 值估计。

2. Actor:策略网络
2.1 定义
策略网络 (Actor) 使用神经网络来近似策略函数:
π(a∣s)≈π(a∣s;θ)
其中 θ 是神经网络的可训练参数。
2.2 输入与输出
- 输入:状态 s,例如游戏画面的一帧截图
- 输出:动作空间上的概率分布
2.3 网络架构
1
2
3
4
5
6
7
8
9
| 状态 s (游戏画面)
↓
卷积层 (Conv) → 提取图像特征
↓
全连接层 (Dense)
↓
Softmax 层 → 输出概率分布
↓
{"left": 0.2, "right": 0.1, "up": 0.7}
|
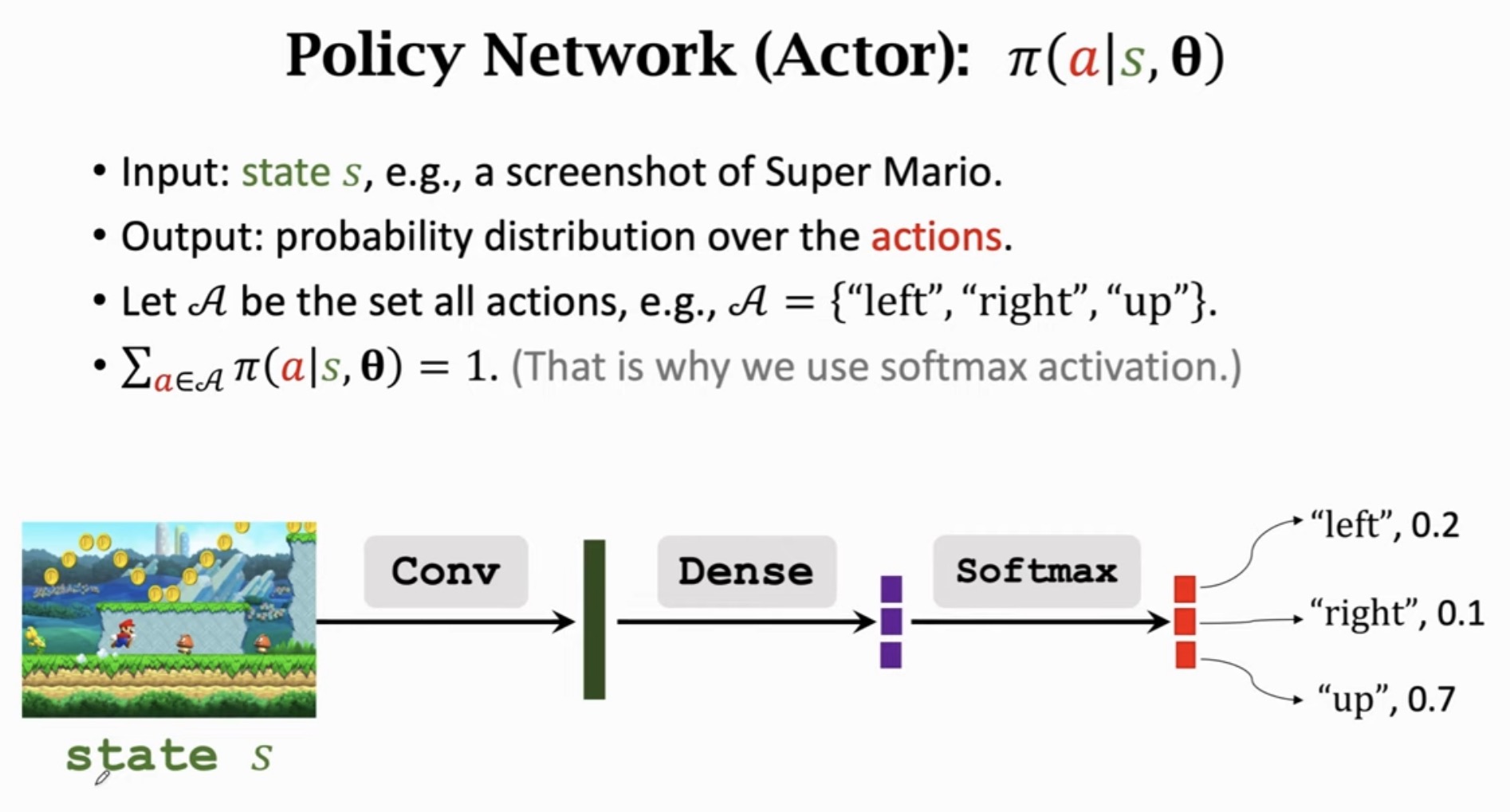
2.4 Softmax 输出
输出是合法的概率分布,所有动作概率之和为 1:
a∈A∑π(a∣s;θ)=1
这就是为什么输出层使用 Softmax 激活函数。
3. Critic:价值网络
3.1 定义
价值网络 (Critic) 使用神经网络来近似动作价值函数:
Qπ(s,a)≈q(s,a;w)
其中 w 是神经网络的可训练参数。
3.2 输入与输出
- 输入:状态 s 和动作 a
- 输出:近似的动作价值(一个标量 q(s,a;w))
3.3 网络架构
价值网络的核心设计是双流输入、拼接特征:
1
2
3
4
5
| 状态 s (图像) 动作 a (离散值)
↓ ↓
Conv Dense
↓ ↓
特征向量 ──→ [拼接 concatenate] ──→ Dense ──→ q(s, a; w)
|
具体流程:
- 状态 s 通过卷积层提取图像特征
- 动作 a 通过全连接层编码为特征
- 两组特征拼接后,通过全连接层输出一个标量值
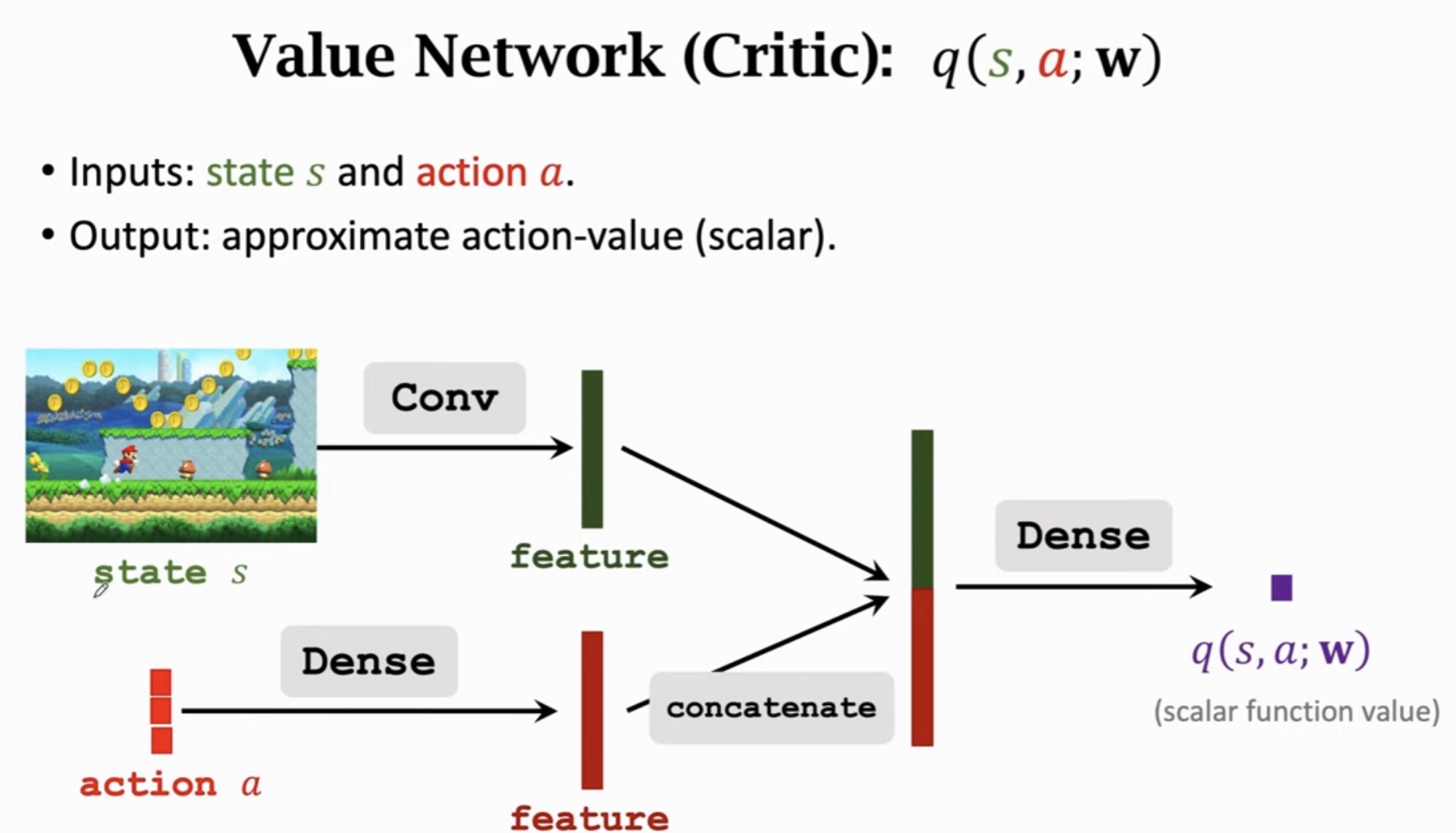
3.4 为什么需要动作作为输入?
与 DQN 不同(只需要状态作为输入),Critic 网络需要同时输入状态和动作,因为它要估计的是 Q(s,a),即在特定状态下采取特定动作的价值。
4. 状态价值函数近似
4.1 真实状态价值函数
Vπ(s)=a∑π(a∣s)⋅Qπ(s,a)
4.2 使用神经网络近似
用 Actor 网络 π(a∣s;θ) 近似策略,用 Critic 网络 q(s,a;w) 近似 Q 值:
V(s;θ,w)=a∑π(a∣s;θ)⋅q(s,a;w)
4.3 双网络协作
| 组件 |
网络 |
参数 |
功能 |
| Actor |
π(a∥s;θ) |
θ |
选择动作 |
| Critic |
q(s,a;w) |
w |
评估动作 |
这两个网络共享同一个优化目标——最大化 V(s;θ,w),但通过不同的方式更新。
5. 训练流程
Actor-Critic 的每个时间步需要完成以下操作:

整体步骤
- 观察状态 st
- 采样动作 at∼π(⋅∣st;θt)
- 执行动作 at,环境返回新状态 st+1 和奖励 rt
- 更新 Critic:用时序差分 (TD) 更新价值网络参数 w
- 更新 Actor:用策略梯度更新策略网络参数 θ
关键点:每个时间步都可以进行更新,不需要等到 episode 结束。这是相比 REINFORCE 的一大优势。
6. 更新价值网络:时序差分
6.1 TD 目标
Critic 使用时序差分 (Temporal Difference, TD) 方法进行训练。
首先计算两个 Q 值估计:
- 当前 Q 值:q(st,at;wt)
- 下一状态 Q 值:q(st+1,at+1;wt)
TD 目标定义为:
yt=rt+γ⋅q(st+1,at+1;wt)
其中 γ 是折扣因子。
6.2 损失函数
TD 损失使用均方误差:
L(w)=21[q(st,at;w)−yt]2
6.3 梯度下降更新
对 w 使用梯度下降最小化损失:
wt+1=wt−α⋅∂w∂L(w)∣∣∣∣w=wt
其中 α 是 Critic 的学习率。

6.4 TD 误差
将损失函数展开后的梯度为:
∂w∂L(w)=[q(st,at;w)−yt]⋅∂w∂q(st,at;w)
其中方括号中的项就是 TD 误差 (TD error):
δt=q(st,at;w)−(rt+γ⋅q(st+1,at+1;w))
因此最终的更新公式为:
wt+1=wt−α⋅δt⋅∂w∂q(st,at;w)∣∣∣∣w=wt
7. 更新策略网络:策略梯度
7.1 策略梯度回顾
状态价值函数对 θ 的导数(策略梯度)为:
∂θ∂V(s;θ,w)=EA[∂θ∂logπ(A∣s;θ)⋅q(s,A;w)]
7.2 定义辅助函数
令:
g(a,θ)=∂θ∂logπ(a∣s;θ)⋅q(s,a;w)
则策略梯度可以写成:
∂θ∂V(s;θ,w)=EA[g(A,θ)]
7.3 随机策略梯度上升
由于期望无法精确计算,通过采样来近似:
- 随机采样:a∼π(⋅∣st;θt)(因此 g(a,θ) 是无偏估计)
- 梯度上升:
θt+1=θt+β⋅g(a,θt)
其中 β 是 Actor 的学习率。
展开写即为:
θt+1=θt+β⋅q(st,at;w)⋅∂θ∂logπ(at∣st;θ)∣∣∣∣θ=θt

8. 完整算法
8.1 Actor-Critic 算法(9步)
每一步的具体操作如下:
步骤 1-3:交互与采样
1. 观察状态 st, 采样动作 at∼π(⋅∣st;θt)2. 执行 at, 环境返回 st+1 和 rt3. 采样虚拟动作 a~t+1∼π(⋅∣st+1;θt)(不执行!)
注意:步骤 3 中 a~t+1 是虚拟动作,仅用于计算 Q 值估计,不会在环境中执行。
步骤 4-5:计算 TD 误差
4. 评估价值网络:qt=q(st,at;wt),qt+1=q(st+1,a~t+1;wt)5. 计算 TD 误差:δt=qt−(rt+γ⋅qt+1)
步骤 6-7:更新 Critic
6. 计算 Critic 梯度:dw,t=∂w∂q(st,at;w)∣∣∣∣w=wt7. 更新价值网络:wt+1=wt−α⋅δt⋅dw,t
步骤 8-9:更新 Actor
8. 计算 Actor 梯度:dθ,t=∂θ∂logπ(at∣st;θ)∣∣∣∣θ=θt9. 更新策略网络:θt+1=θt+β⋅qt⋅dθ,t

8.2 算法流程图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| ┌────────────────────────────────────────────────────────────┐
│ Actor-Critic 算法流程 │
├────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────────────────────────────────────────┐ │
│ │ 1. 观察状态 s_t │ │
│ │ 2. 采样动作 a_t ~ π(·|s_t; θ_t) │ │
│ │ 3. 执行 a_t → 获得 s_{t+1}, r_t │ │
│ │ 4. 采样虚拟动作 ã_{t+1} ~ π(·|s_{t+1}; θ_t) │ │
│ └──────────────────┬───────────────────────────┘ │
│ ↓ │
│ ┌──────────────────────────────────────────────┐ │
│ │ Critic 更新 (TD学习) │ │
│ │ 5. q_t = q(s_t, a_t; w) │ │
│ │ q_{t+1} = q(s_{t+1}, ã_{t+1}; w) │ │
│ │ 6. δ_t = q_t - (r_t + γ·q_{t+1}) │ │
│ │ 7. w_{t+1} = w_t - α·δ_t·∂q/∂w │ │
│ └──────────────────┬───────────────────────────┘ │
│ ↓ │
│ ┌──────────────────────────────────────────────┐ │
│ │ Actor 更新 (策略梯度) │ │
│ │ 8. d_θ,t = ∂log π(a_t|s_t,θ)/∂θ │ │
│ │ 9. θ_{t+1} = θ_t + β·q_t·d_θ,t │ │
│ └──────────────────┬───────────────────────────┘ │
│ ↓ │
│ 进入下一个时间步 t+1 │
│ │
└────────────────────────────────────────────────────────────┘
|
9. 带Baseline的策略梯度
9.1 问题动机
在原始算法步骤 9 中,Actor 使用 qt 作为策略梯度的权重:
θt+1=θt+β⋅qt⋅dθ,t
问题在于 qt 的绝对值可能很大,导致梯度更新不稳定。我们需要一个基线 (baseline) 来减小方差。
9.2 使用 TD 误差作为 Baseline
改进方法:用 TD 误差 δt 代替 qt:
θt+1=θt+β⋅δt⋅dθ,t
展开为:
θt+1=θt+β⋅δt⋅∂θ∂logπ(at∣st;θ)∣∣∣∣θ=θt

9.3 TD 误差的作用
δt=qt−(rt+γ⋅qt+1)
TD 误差的含义:
- δt>0:当前 Q 值估计高于实际回报,当前动作的实际效果不如预期
- δt<0:当前 Q 值估计低于实际回报,当前动作的实际效果好于预期
通过 δt 作为权重,策略梯度可以更准确地判断哪些动作应该被增强(δt<0 时),哪些应该被抑制(δt>0 时)。
注意:严格来说,(rt+γ⋅qt+1) 才是 baseline,δt 是相对于 baseline 的偏差。
9.4 两种版本对比
|
原始版本 |
带 Baseline 版本 |
| Actor 更新 |
θt+1=θt+β⋅qt⋅dθ,t |
θt+1=θt+β⋅δt⋅dθ,t |
| 权重 |
qt(原始 Q 值) |
δt(TD 误差) |
| 方差 |
较大 |
较小 |
| 稳定性 |
较差 |
更好 |
9.5 完整算法(带 Baseline)
1
2
3
4
5
6
7
8
9
| 1. 观察状态 s_t,采样 a_t ~ π(·|s_t; θ_t)
2. 执行 a_t → 获得 s_{t+1}, r_t
3. 采样虚拟动作 ã_{t+1} ~ π(·|s_{t+1}; θ_t) (不执行!)
4. q_t = q(s_t, a_t; w_t), q_{t+1} = q(s_{t+1}, ã_{t+1}; w_t)
5. δ_t = q_t - (r_t + γ·q_{t+1})
6. d_w,t = ∂q(s_t,a_t;w)/∂w |_{w=w_t}
7. w_{t+1} = w_t - α·δ_t·d_w,t ← Critic 更新
8. d_θ,t = ∂log π(a_t|s_t,θ)/∂θ |_{θ=θ_t}
9. θ_{t+1} = θ_t + β·δ_t·d_θ,t ← Actor 更新 (带 Baseline)
|
10. 概念关系总结
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| ┌──────────────────────────────────────────────────────────────┐
│ Actor-Critic 方法 │
├──────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────┐ ┌─────────────┐ │
│ │ Actor │ │ Critic │ │
│ │ 策略网络 │ │ 价值网络 │ │
│ │ │ │ │ │
│ │ π(a|s; θ) │ │ q(s,a; w) │ │
│ │ │ │ │ │
│ │ 输出:概率 │ │ 输出:标量 │ │
│ │ 用途:选动作│ │ 用途:评分 │ │
│ └──────┬──────┘ └──────┬──────┘ │
│ │ │ │
│ │ ────── V(s;θ,w) ────────────── │ │
│ │ = Σ π(a|s;θ)·q(s,a;w) │ │
│ │ │ │
│ 策略梯度更新 TD 梯度下降更新 │
│ │ │ │
│ θ ← θ + β·δ_t·∂logπ/∂θ w ← w - α·δ_t·∂q/∂w │
│ (带Baseline) (最小化TD误差) │
│ │
│ ───────────────────────────────────────────────── │
│ 共享信息:δ_t = q_t - (r_t + γ·q_{t+1}) │
│ TD 误差同时驱动两个网络的更新 │
│ │
└──────────────────────────────────────────────────────────────┘
|
Actor-Critic vs 纯策略梯度 vs 纯价值方法
| 特性 |
REINFORCE (纯策略) |
Actor-Critic |
DQN (纯价值) |
| 学习目标 |
π(a∥s;θ) |
π(a∥s;θ) + q(s,a;w) |
Q(s,a) |
| Q 值来源 |
完整轨迹回报 |
Critic 网络 |
目标网络 |
| 更新时机 |
Episode 结束后 |
每个时间步 |
每个时间步 |
| 方差 |
高 |
中 |
低 |
| 适用动作空间 |
离散 + 连续 |
离散 + 连续 |
主要离散 |
| 偏差 |
无偏 |
有偏 |
有偏 |
数学符号汇总
| 符号 |
含义 |
| π(a∥s;θ) |
Actor 策略网络 |
| θ |
Actor 网络参数 |
| β |
Actor 学习率 |
| q(s,a;w) |
Critic 价值网络 |
| w |
Critic 网络参数 |
| α |
Critic 学习率 |
| V(s;θ,w) |
近似状态价值函数 |
| yt |
TD 目标 |
| δt |
TD 误差 |
| dw,t |
Critic 梯度 |
| dθ,t |
Actor 梯度 |
| γ |
折扣因子 |
| a~t+1 |
虚拟采样动作(不执行) |
核心公式速查
1. 状态价值近似
V(s;θ,w)=a∑π(a∣s;θ)⋅q(s,a;w)
2. TD 目标
yt=rt+γ⋅q(st+1,a~t+1;wt)
3. TD 误差
δt=q(st,at;wt)−(rt+γ⋅q(st+1,a~t+1;wt))
4. Critic 更新(梯度下降)
wt+1=wt−α⋅δt⋅∂w∂q(st,at;w)∣∣∣∣w=wt
5. Actor 更新(策略梯度,原始版本)
θt+1=θt+β⋅qt⋅∂θ∂logπ(at∣st;θ)∣∣∣∣θ=θt
6. Actor 更新(策略梯度,带 Baseline)
θt+1=θt+β⋅δt⋅∂θ∂logπ(at∣st;θ)∣∣∣∣θ=θt